
-1.png)


Have you or a loved one been affected by an expired SSL certificate?
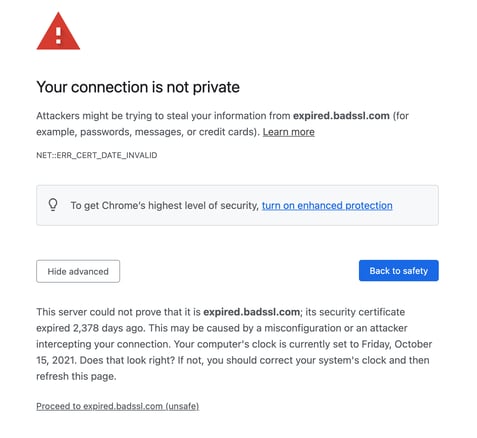
Despite how common this issue is and how impactful it is to users, expired SSL certificates still plague our web apps. It’s not a particularly novel issue, but it still catches us all by surprise now and again, and the RCAs seem to have a common sociotechnical theme. Preventing an expired cert outage isn’t usually a challenge due to technical complexity. More often than not, it’s an unexpected result of the fuzzy boundaries between people, machines, and processes.
So what goes wrong?
Sometimes a warning notification gets sent to the wrong person or to a group alias where nobody was explicitly responsible for rotating things. Sometimes it’s sent to the right team, but it slipped out of their mind when something more urgent showed up in the pipeline. Sometimes, terrifyingly, the notification isn’t sent out until the cert is already expired, turning a standard cert rotation workflow into an urgent embarrassing Sev0.
Whatever the reasons, there’s still some room for improvement. I work on an SLO platform, so I’m biased, but an SLO can be a tremendous additional risk mitigation tool for these types of incidents.
Now, I’m a fan of the swiss cheese model, and in that approach, an SLO is just one layer of protection. We’re not getting rid of notifications or automated cert rotation; we’re just bringing in another tool that can help patch some gaps in the existing process.
Alright, so what does a Cert Health SLO bring to the table?
Great question! I’m glad you asked.
- It unifies the team around a single definition of health. Everyone agrees that an expired cert is no longer “healthy.” But what about one minute before? One day before? Getting everyone on the same page about when to rotate a cert makes it easy to determine when to escalate that work.
- It communicates cert health in a framework that’s already familiar across the product and engineering organizations. There’s no more need to pitch the importance of this operational work or figure out how to prioritize it — it fits into your existing SLO workflow and cadence.
- It’s a repeat reminder. Whether your on-call is checking in on SLO performance or your product team is evaluating room for new feature work, having Cert Health show up during regular operational review cycles makes rotation less likely to fall through the cracks.
How does it all work?
There’s more than one way to swing a bat, and the same is true with SLOs. Here’s what worked for us.
Step 1: Figure out the SLO stakeholders.
We knew we’d be using a date well before cert expiration to drive new rotation work so that work would stay manageable and stress-free. When our cert rotation process doesn’t work as expected, we’re left scrambling, reprioritizing, and fighting fires. This SLO will help us measure and manage these incidents, making us both its owners and stakeholders.
Step 2: Define “Cert Health”
For us, this meant a cert was valid and had sufficient time left before expiration. We settled on two weeks in our Dev environment and four weeks in Prod – less than that, and folks started to feel a bit uncomfortable. The discussion here was surprisingly similar to that around a Latency SLO – We knew what Very BadTM looked like and worked backward from that until we were happy.
Step 3: Set up a Service Level Indicator (SLI)
We had metrics that reported, on a regular cadence, how much time remained for certs across our various applications. Every data point we receive counts towards our Valid occurrences. Each data point with a value over our agreed-upon thresholds (ex. More than four weeks remaining) counts as a Good occurrence. Each measurement interval, we see something like (18 servers with certificates with time_to_expiry > 4 weeks) / (18 servers reported).
Step 4: Setup a Performance Target
To balance out the high impact of each failed cert check with our current approach to prioritizing operational work, we chose a target of 95% to start. Overall performance and error budget burn rates will vary depending on the number of servers monitored and the check rate, so this is something we’re planning to revisit every once in a while.
Nobl9 Setup Steps
Open the SLO Wizard and select the appropriate Service and Data Source
Since this functionality touches on a few different applications but is managed through the same process, we’re putting it in our Infrastructure service.
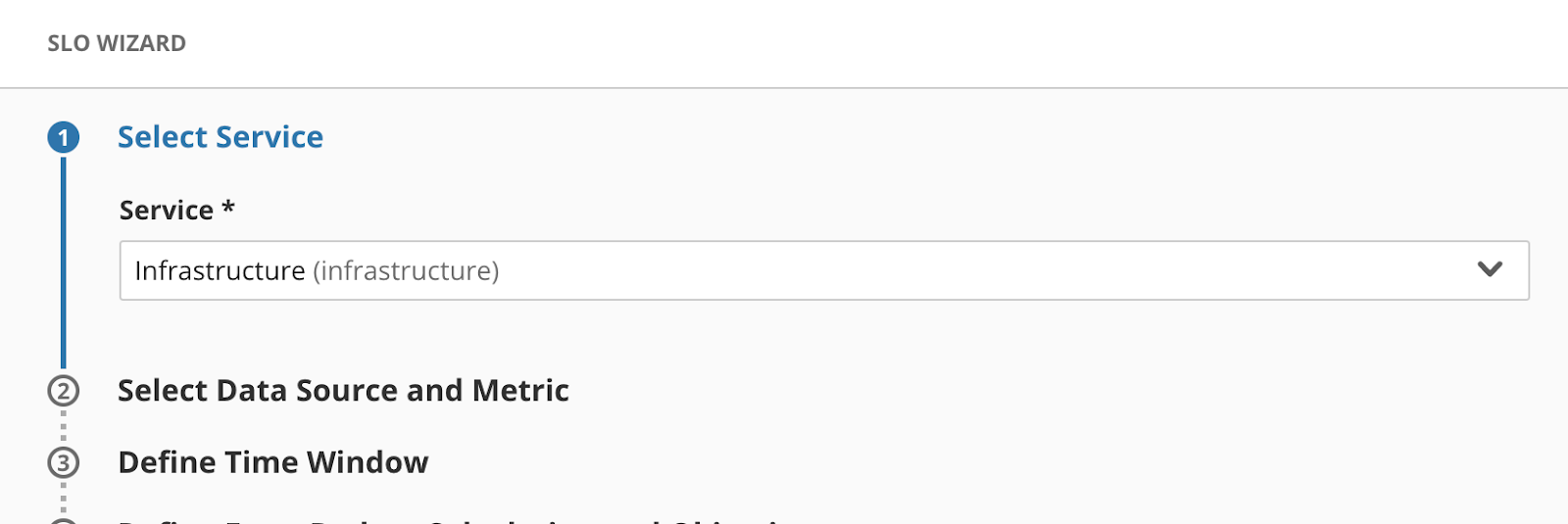
Choose the appropriate data source and add some queries
We’re using a Ratio Metric, and as mentioned above, we’ve got a query for Good Metrics that counts the total number of datapoints showing > 4 weeks of remaining time and a Total Metrics query that just counts all datapoints received.
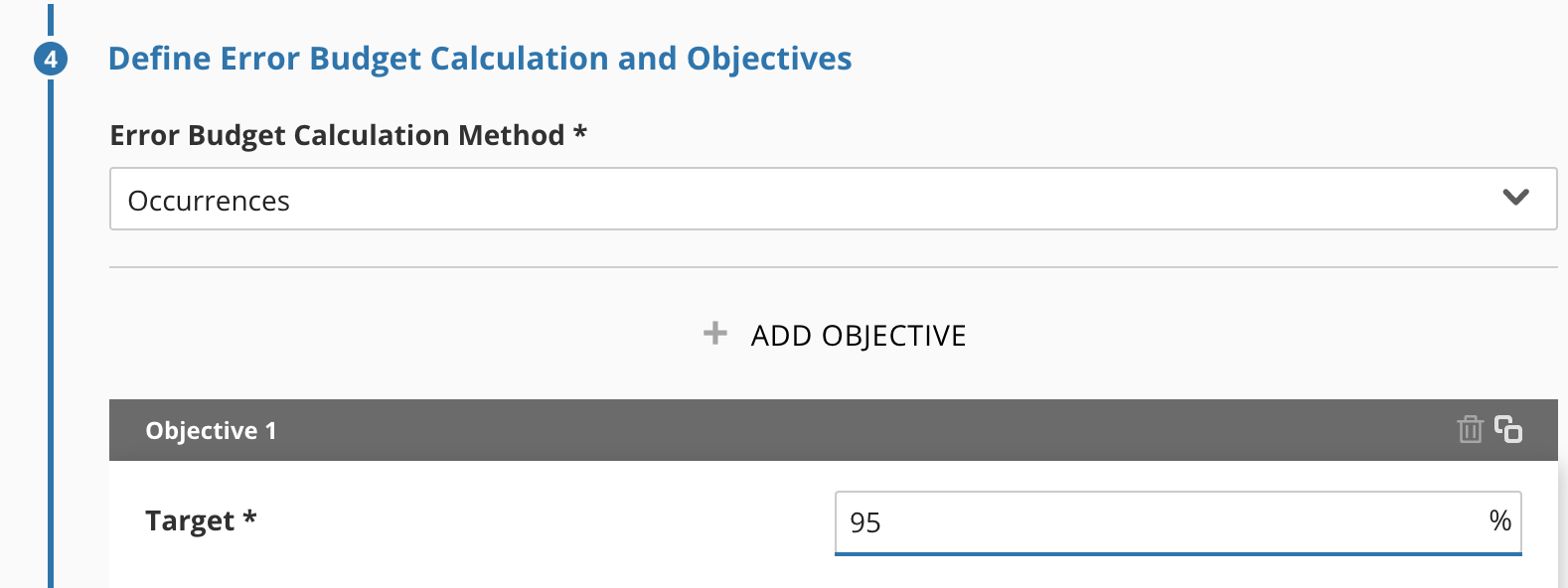
Define our Time Windows, Target, and Calculation Method
Most of our SLOs are already on a 28d rolling window, so we’ll snap to that. Since we’re dealing with raw event counts, we want to use the Occurrences method for Error Budget calculation, and we’ve already got our performance target of 95%.
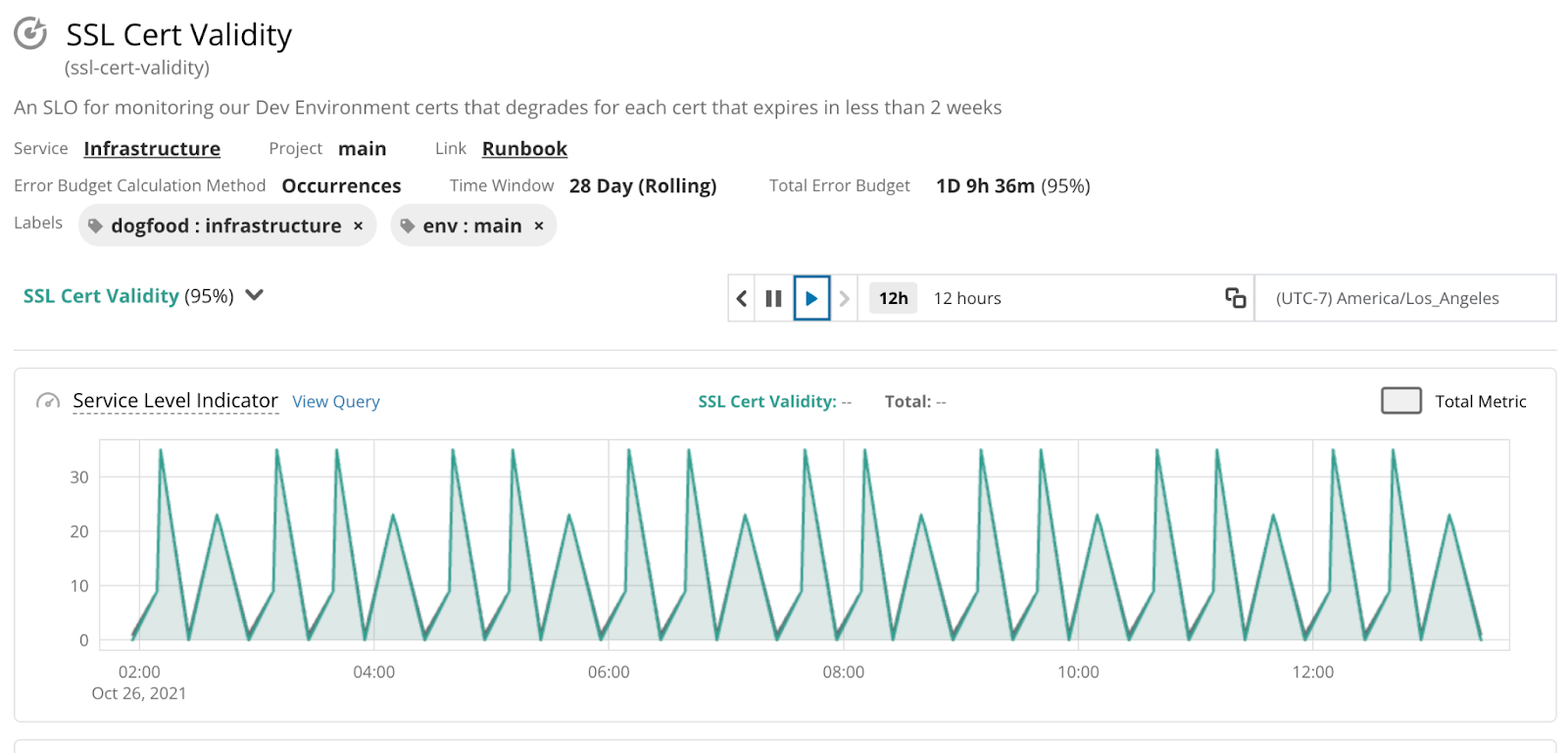
Add helpful metadata
For the last stage in the wizard we can add any additional info to the SLO that will help us track and manage it later. There are a few Labels we want to include and a Runbook link, so we can add those here! Then all we have to do is Save SLO and watch our perf data pour in.
apiVersion: openslo/v1alpha
kind: SLO
metadata:
displayName: SSL Cert Validity
name: SSL Cert Validity
labels:
dogfood: infrastructure
env: main
runbook: go/runbook-cert-validity
spec:
description: An SLO for monitoring our Dev Environment certs that degrades for each cert that expires in less than 2 weeks
service: Infrastructure
budgetingMethod: Occurrences
objectives:
- ratioMetrics:
counter: false
good:
source: YourTelemetryProvider
queryType: customQuery
query: Count of certs with > 4 weeks until expiry
total:
source: YourTelemetryProvider
queryType: customQuery
query: Count of certs
target: 0.95
timeWindows:
- count: 28
isRolling: true
unit: Day
So, is this the right SLO for my team?
I’m sure you saw this answer coming – “It depends.” There’s no cut and dry answer for these kinds of questions, but part of the beauty of the SLO Framework is its focus on progress, not perfection.
This SLO, like many SLOs, can be a great way to learn more about your team, your team’s ownership boundaries, and the performance expectations connected to your services. It can be a way to dive deeper on your existing cert management strategy, or on the telemetry you’ve got around it.
Cert expiration is not a typical SLO. If you’re just getting started with SLOs, it probably isn’t the best place to start. If you’re already familiar with SLOs, if your team already reviews them on a regular basis and if they’re an existing part of your operational strategy, it could fit in nicely as an extra layer of protection against a high visibility incident.
Share:







Do you want to add something? Leave a comment