
-1.png)


An Intellyx BrainBlog for Nobl9, by Jason English
“We must stand firm between two kinds of madness: the belief that we can do anything; and the belief that we can do nothing.” – Alain
In our previous Intellyx post, we outlined how the modern SLO outshines the traditional SLA (service level agreement) in aligning the organization around measured improvements in the reliability and performance of complex software and systems to meet business goals.
SLAs are useful for legally guaranteeing a baseline level of performance in a contract, but by nature they set up a pass/fail test for the hapless system owner, rather than a path toward improvement. By the time an SLA is triggered, the customer is already unhappy and penalties may already be in the works.
On the other hand, the SLO allows a ‘fuzzy edge’ of success, where an acceptable range of failure–or error budget–can still be accounted for.
Prioritization of SLOs and underlying SLIs (service level indicators) makes all the difference in how we set application and system reliability goals that will incentivize the continuous improvement of customer experience, rather than merely attempting to avoid the risk of SLA failures.
Driving the risk/reward economics of incentives
“Incentive structures work, so you have to be very careful of what you incent people to do, because various incentive structures create all sorts of consequences that you can’t anticipate.”
― Steve Jobs
Economics is not just about money — instead, it is essentially the study of incentives, and their effect on the behavior of humans. As business organizations are made up of humans, a business in its simplest terms seeks out positive incentives like increased revenue and returning customers, while moving away from negative ones, like lost revenue and unexpected costs.
The primary economic incentives for the business should, logically, also drive how engineers design business systems that support customer and operational needs. Still, can we reach a place where too much adherence to economic incentives lets the business, and its underlying systems down?
Delivering on a pizza-performance parable from the consumer world
For an illustration, let’s consider a physical-world business SLO example from the consumer retail world rather than a system-level one. Remember the old Domino’s Pizza “Delivered in 30 minutes, or it’s Free” promise?
It was an innovative incentive for encouraging more sales for the company, while increasing satisfaction — if customers get the pizza fast, they’re happy, and if it arrives late, they get the perk of a free pizza to make up for it.
There was an unfortunate bug within this pledge though: the pizza delivery driver loses out on tips if they fail to make it to the customer’s door in 30 minutes — even if the tardiness was beyond the driver’s control.
Some hurried delivery drivers had serious traffic accidents, which resulted in liability lawsuits and punitive damages against the company and its franchisees, and ultimately, Domino’s cancelling the policy.
Interestingly, even though the 30-minute guarantee may not have significantly increased the normal risk of driver accidents, the incentives looked like they caused drivers to speed — especially to jurists and judges in this case.
What can our 2-pizza application delivery teams take away from this pizza parable when prioritizing SLOs? The business will always want dev teams to deliver innovation to customers faster, and ops teams to target higher reliability, but we can’t afford to get too distracted by short-term metrics and localized results that can hide future risks as our systems scale.
Aligning system performance with business performance
If every modern business is essentially becoming a software company, then the software and infrastructure still needs to serve business needs first, before service reliability goals.
SLOs form a bridge of better understanding across the divide between technology and business teams by providing a shared context of value — distilling down the complexity of incoming latency, performance and error feeds into a shared success rating that all stakeholders can agree upon.
One fast growing financial services startup faced just such a huge challenge — with the business side demanding the rapid delivery of new competitive differentiating features for its application suite, while technology teams struggled to prevent unacceptable service downtimes and SLA failures due to the constant change and increasing scale of customer usage.
They tried to rework some of their existing APM (application performance monitoring) tooling to provide inputs to SLOs, but without a business context, metrics like response time, traffic and errors could only offer signals into what was happening.
Using the purpose-built Nobl9 SLO platform, the firm sought to elevate a shared culture of ‘value reliability,’ merging incoming SLIs with the goals of business value and system reliability– to define SLOs that could answer key questions across three time horizons: operational, tactical and strategic.
This enabled them to ask very different questions of their SLOs:
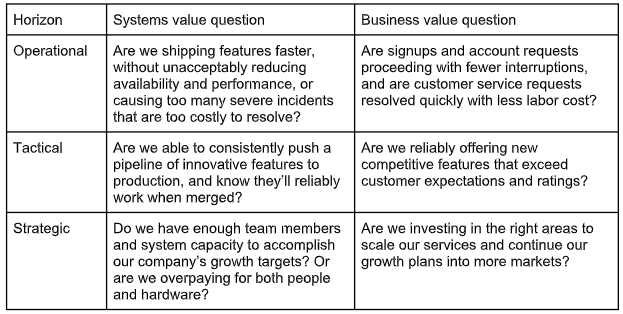
The value of SLOs when properly defined and prioritized between systems and business teams can’t be underestimated.
The Intellyx Take
As you might expect, the alignment of shared incentives around SLOs isn’t just a system the company buys, it must be accompanied by a cultural change.
Linking service reliability and performance to business goals allows all employees and partners to know which SLOs they are responsible for, and the impact they are making with each new feature delivered or customer issue resolved.
However, the ingestion of SLI measurements into SLOs can rapidly create a recurring annuity of its own, especially at increasing scale as the practice is adopted across an extended organization. Teams should spend time on projects that make software more useful and systems more reliable, and as little time as possible interpreting and managing SLOs.
Traditional IT Ops teams used to have a more intimate understanding of the systems they supported. Since automation by nature can effectively triple the number of systems and change events under an individual SRE’s management, achieving complete context can become quite overwhelming.
By aligning incentives with SLOs in the production context of observability and Ops management tools, as well as within the software delivery pipeline when changes and new releases are introduced, companies can regain traction against this shifting surface, and measure what matters most.
Copyright ©2021 Intellyx LLC. At the time of publishing, Nobl9 is an Intellyx customer. Intellyx retains final editorial control of this article.
Image Credit: John Schnobrich on Unsplash
Share:







Do you want to add something? Leave a comment