
-1.png)

Table of Contents
Like this article?
Subscribe to our Linkedin Newsletter to receive more educational content
Subscribe nowRunbook example
Runbooks can improve productivity and increase system availability by documenting best practices and defined workflows for specific situations. When well written, their clear and precise nature is instrumental in maintaining order during high-pressure scenarios like outages impacting production services, making them an essential part of any IT incident management toolbox.

The following is an example of a basic runbook to react to HTTP 500 errors in a web application (you can download the ready-to-use runbook for this example at the link above):
|
Description |
The HTTP 500 error indicates a generic server-side issue. |
The server encountered an unexpected condition preventing it from fulfilling a request. |
|
Initial troubleshooting |
Verify the error |
Confirm the 500 error by reloading the webpage. |
|
Inspect server logs |
For Apache: /var/log/apache2/error.log For Nginx: /var/log/nginx/error.log Application Logs: See application documentation for log location |
|
|
Check application code |
Identify the failing module |
Review the logs to pinpoint the code causing the issue. |
|
Debug code locally |
Use debuggers or additional logs to understand the problem. |
|
|
Review recent changes |
Test code deployments |
Roll back recent changes and test if the issue persists |
|
Check for server updates |
Check for updates to the OS, libraries, or dependencies that may have introduced the issue |
|
|
Escalation |
Notify the development team with detailed findings and logs |
Email devteam@example.com mailbox |
|
File a ticket in the appropriate tracking system |
Include error messages, logs, and steps to reproduce. |
|
|
Preventive Measures |
Implement logging and monitoring |
Add any logging and monitoring that could have helped to prevent the situation. |
|
Implement automated testing |
Ensure that automated tests cover critical paths. |
|
|
Notes |
Related errors |
502 Bad Gateway 503 Service Unavailable |
|
References |
This example is far from comprehensive; any experienced SRE team will surely have additional steps based on their needs.
Before going further, it’s worth looking at how runbooks and playbooks differ. The two incident management tools have distinct purposes but are often confused due to their similarities.
Runbooks provide tactical step-by-step instructions for handling specific scenarios. Playbooks define a more strategic approach and document a broader framework that outlines roles, communication plans, and decision-making processes to guide teams. In short, playbooks outline the “what” and “why” of a response, while runbooks focus on “how.” Runbooks and playbooks complement each other to provide a cohesive system for effectively managing IT operations and incidents.
Customer-Facing Reliability Powered by Service-Level Objectives
Service Availability Powered by Service-Level Objectives
Learn More
Integrate with your existing monitoring tools to create simple and composite SLOs

Rely on patented algorithms to calculate accurate and trustworthy SLOs

Fast forward historical data to define accurate SLOs and SLIs in minutes
Customer-Facing Reliability Powered by Service-Level Objectives
Service Availability Powered by Service-Level Objectives
Learn More
Integrate with existing tools and systems
Runbooks should not be treated as standalone entities; integrating them with existing tools and systems where possible improves their workflow. Embedding runbooks into tools commonly used by the team, such as dashboards and portals, improves visibility and efficiency. Integrating incident management platforms to centralize incident tracking and resolution efforts can streamline workflows and offer integration with other tools.
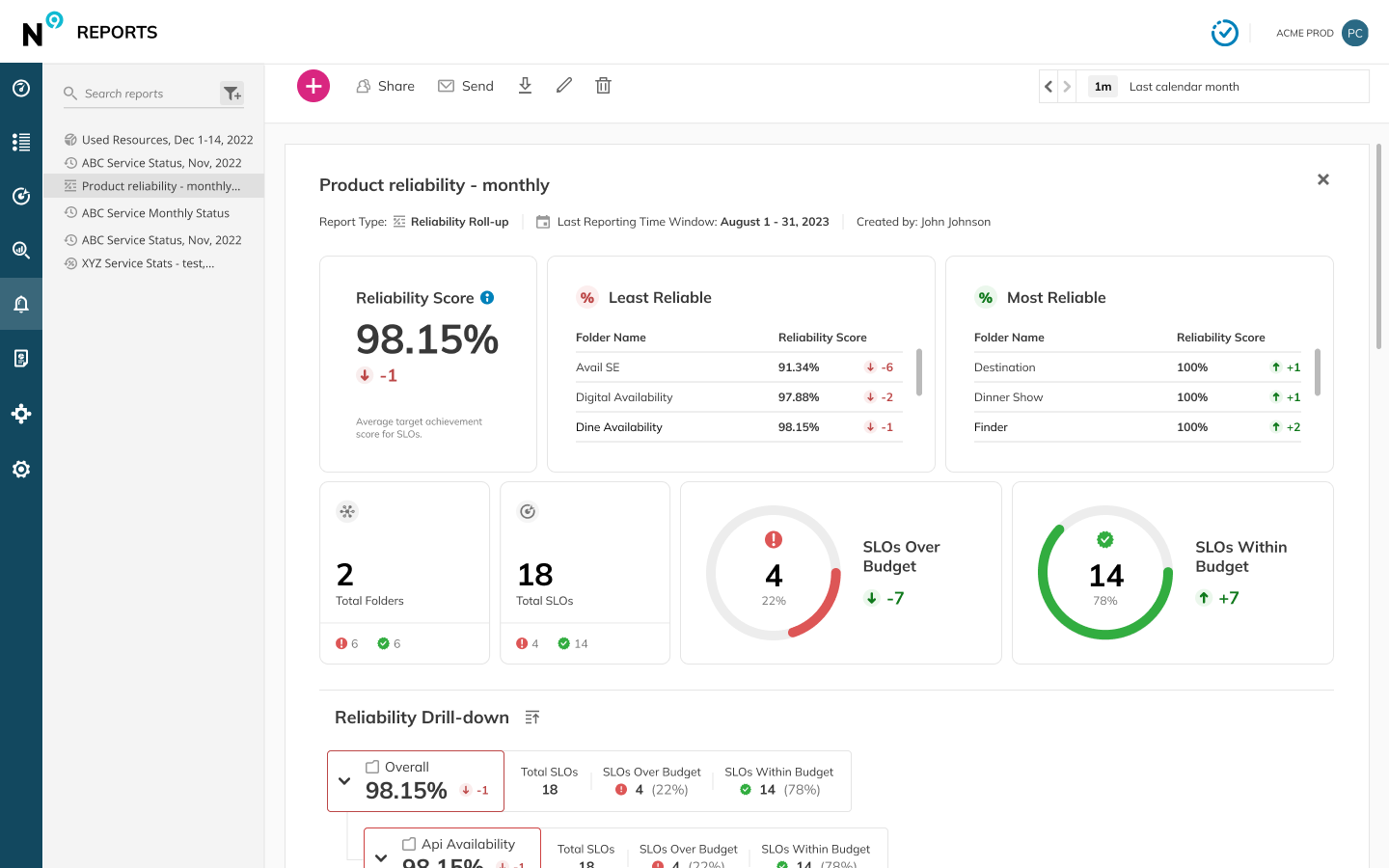
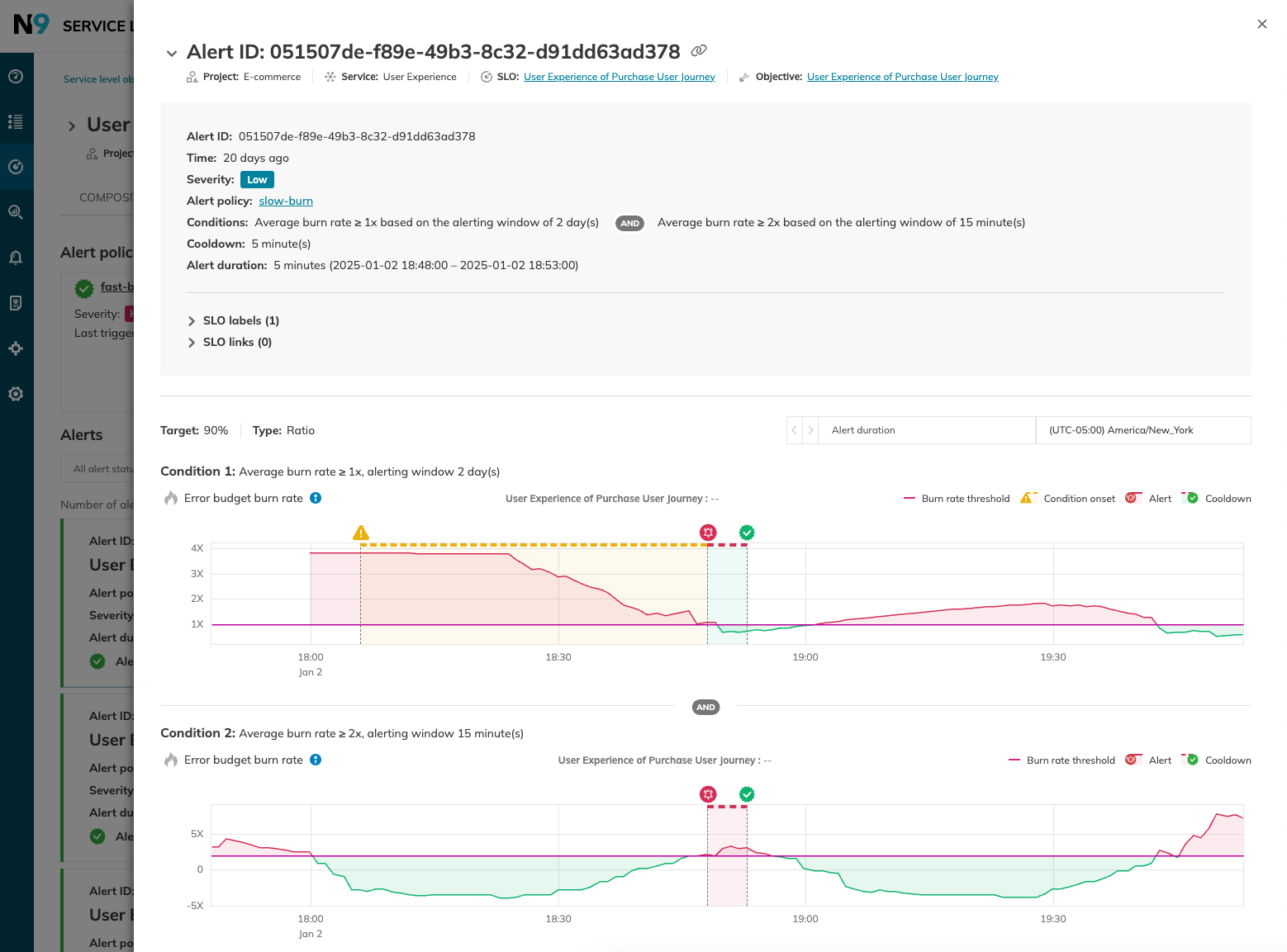
Ensure that your runbooks integrate with monitoring and alerting systems. For example, you could include Nobl9’s error budget adjustments in a decision tree to suggest different reactions to various scenarios or automatically annotate SLO charts when runbooks are triggered to add context to performance data and help identify patterns during post-incident reviews.
Furthermore, you could integrate Nobl9’s SLOs into messaging or notification systems like Slack to prompt to invoke a runbook when an SLO falls below a given value, provide updates on an incident as the value changes, and even confirm resolution if the value returns above a specific level. For example, you could use integrations to post a Slack, Teams, Discord, or PagerDuty message if latency for an application is above a given threshold for 1% of queries. This notifies the team of potential service degradation immediately. A similar notification could be posted once the latency returns below the threshold to confirm that the degradation has been resolved.
Utilizing Nobl9’s low severity burn rate alerts, you can preemptively identify, be notified of, and even address potential service degradation before it escalates. Integration with Slack, for example, is effortlessly configurable via YAML:
apiVersion: n9/v1alpha
kind: AlertMethod
metadata:
name: slack-notification
displayName: slack notification
spec:
description: Sends notification to a Slack channel
slack:
url: <https://hooks.slack.com/services/1234567890/abcdef> Workflow automation tools can provide pre-made remediation scripts for engineers to execute or carry out tasks automatically to reduce human error and speed up incident resolution.
Integration does not necessarily need to be achieved through technical means. Including links and signposts for dashboards or other data collections within the steps of a runbook is also a valid approach. Nobl9’s dashboards can collate data from various sources to provide a single-pane-of-glass view on the status of any service and confirm whether a runbook has the desired effect. Composite SLOs can also be used to check if the service is returning to an acceptable level.
As mentioned, a runbook is only valuable if easily located and accessed. Storing runbooks in a centralized knowledge management system alongside documentation ensures that users can easily access the latest version. Utilizing tags and keywords to provide a searchable database of runbooks and including hyperlinks for faster navigation enhances accessibility.
You should integrate runbooks with ticketing systems to connect incident documentation and task management. This ensures that every action is tracked and associated with the relevant ticket. Automation to trigger escalation workflows when predefined conditions are met can reduce response times and ensure that the right people address the issues.
Furthermore, ChatOps tools enable natural language interaction with your runbooks, enabling the retrieval of information or execution of automated steps directly from a chat platform.
Navigate Chapters: