
-1.png)

Table of Contents
Like this article?
Subscribe to our Linkedin Newsletter to receive more educational content
Subscribe nowIT leaders too often wait until a critical application suffers an outage before investing resources in improving their IT incident management program. Sometimes, the reminder comes as front-page news from a well-known website, like in 2019 when Costco suffered a website outage on Black Friday, the holiday shopping season’s peak traffic day. The outage cost the company $11 million in sales and a 3.6% decrease in monthly revenue.
When the time comes to improve the company’s IT management program, IT leaders who manage applications based on traditional architectures usually turn to ITIL (which the British government pioneered in the 1980s) for recommendations to strengthen the processes ITIL refers to as incident and problem management. The leaders who manage distributed applications that are continuously updated typically turn to Site Reliability Engineering (SRE) best practices (which Google introduced in 2003).
Even though ITIL and SRE best practices differ in many ways, they agree that an IT incident management program must consider people, processes, and tools, measure incidents' impact on users, and identify and fix the root causes of incidents after they are resolved.
In other words, regardless of your application architecture, you would be safe to rely on the following timeless directives when implementing an IT incident management program:
- Identify relevant metrics, logs, events, and traces, as well as fine-tune alerts.
- Define service level objectives (SLOs) and continuously review and improve them.
- Formalize the roles and responsibilities and document escalation procedures.
- Document detailed runbooks that outline specific steps to recover from common failure scenarios.
- Conduct post-incident retrospectives to fix the problems at their roots.

This article recommends best practices for designing or improving such a program. It goes beyond making recommendations to include examples and configuration instructions using open-source tools so the practitioners reading this article can implement the recommendations relevant to their application environments.
Customer-Facing Reliability Powered by Service-Level Objectives
Service Availability Powered by Service-Level Objectives
Learn More
Integrate with your existing monitoring tools to create simple and composite SLOs

Rely on patented algorithms to calculate accurate and trustworthy SLOs

Fast forward historical data to define accurate SLOs and SLIs in minutes
Define service level objectives
Service Level Objectives (SLOs) transform raw monitoring data into measures of user experience, focusing on what matters to customers rather than just system metrics. For an e-commerce platform, for example, monitoring individual components provides the required data, but SLOs transform this data into measures of service quality that matter to customers and the business. While application servers might report 95% CPU utilization and databases show 1000 queries per second, customers care about whether they can complete their purchases quickly and reliably.
Understanding basic SLO components
Staying with our e-commerce platform example, a checkout completion SLO would demonstrate how metrics combine into meaningful measurements. When an SLO states that 99.9% of checkout attempts must be completed within 3 seconds, it requires monitoring and correlating data from multiple systems:
- Frontend servers measure initial page load and API response times
- Shopping cart services track item addition and price calculation speed
- Payment gateways report transaction processing times
- Inventory systems monitor stock check accuracy
- Order processing tracks confirmation delivery
Setting accurate SLOs depends on historical data analysis and sophisticated calculations. A platform processing millions of transactions generates patterns that help predict degradation and set appropriate thresholds. These patterns also expose unexpected relationships between components - for instance, operations teams might discover that slow product image loading times (due to high traffic and not enough hosting resources) consistently precede checkout slowdowns by a few minutes, which can be a leading indicator to scale resources preemptively.
Composite SLOs
While most monitoring tools can track simple SLOs, complex application platforms with multiple interconnected services must rely on composite SLOs. However, the technology behind composite SLOs has evolved significantly in recent years.
A traditional composite SLO combines metrics from different sources to provide a complete picture of service health. For instance, an e-commerce checkout workflow must process data from payment gateways, inventory systems, and user sessions.
However, traditional composite SLO implementations face significant limitations. They often restrict data sources to a single project, support only a single level of hierarchies, and treat all components equally regardless of their business importance. These limitations can lead to missed patterns or unreliable results when dealing with distributed systems and varying traffic patterns.
Modern composite SLOs
Modern composite SLOs (you can think of them as the 2.0 version of composite SLOs) overcome these limitations. They provide insights into complex systems from a single entry point down to the smallest component, helping teams have complete visibility of system reliability. Operations teams can combine many components per SLO across different data sources and projects, creating multi-level hierarchies that reflect their service architecture.
Consider this multi-level composite SLO for an e-commerce checkout flow (using Nobl9’s sloctl’s API):
apiVersion: n9/v1alpha
kind: SLO
metadata:
name: checkout-composite
displayName: Checkout Flow Reliability
project: ecommerce
labels:
key:
- service
- tier
value:
- checkout
- critical
spec:
description: Composite SLO for the entire checkout process flow
alertPolicies:
- checkout-degradation
- payment-failure
budgetingMethod: Occurrences
objectives:
- displayName: Checkout Experience
name: checkout-objective
target: 0.99
composite:
maxDelay: 5m
components:
objectives:
- project: frontend-monitoring
slo: user-experience
objective: frontend-latency
displayName: Frontend Performance
weight: 0.4
whenDelayed: CountAsGood
- project: payment-system
slo: transaction-processing
objective: payment-success
displayName: Payment Processing
weight: 0.6
whenDelayed: CountAsBad
- project: inventory
slo: stock-management
objective: inventory-accuracy
displayName: Inventory Accuracy
weight: 0.5
whenDelayed: Ignore
service: checkout-service
timeWindows:
- unit: Day
count: 28
isRolling: true
calendar:
timeZone: UTC
This hierarchical structure enables sophisticated reliability monitoring through a properly defined YAML configuration. Each component in the composite SLO carries a weight that reflects its business importance. In this example, payment processing (weight 0.6) has the highest priority, followed by inventory accuracy (0.5) and frontend performance (0.4). These weights help teams focus their attention on the system's critical parts.
The configuration handles real-world complexity through several mechanisms. The `maxDelay` setting of 5 minutes provides a buffer for data collection delays, while the `whenDelayed` parameter for each component determines how to handle missing data. Frontend metrics count as successful when delayed (CountAsGood), payment processing failures count against the SLO (CountAsBad), and delayed inventory data is ignored. This flexibility maintains accurate reliability measurements even when monitoring systems experience temporary issues.
The SLO configuration also includes practical operational elements. Alert policies trigger different responses for general checkout degradation versus payment failures. The 28-day rolling window provides a balanced view of system reliability, while labels help categorize and filter SLOs across the organization.
For this purpose, organizations increasingly turn to specialized platforms that can:
- Handle complex multi-service dependencies and integrations with all the leading monitoring tools
- Maintain calculation accuracy at scale using advanced algorithms and adapt to changing traffic patterns.
Combining composite SLOs with the replay functionality helps users create advanced SLOs and test them in minutes instead of waiting weeks for fine-tuning.
Leading-edge SLO solutions allow users to replay months of historical data in fast-forward mode in minutes to determine the appropriate SLO configuration, saving weeks of trial and error. You can learn more about the SLO replay functionality on this page.
Managing error budgets with composite SLOs
Error budgets translate SLOs into practical operational guidance. When setting a 99.9% uptime SLO, teams accept that 0.1% downtime is acceptable—this translates to 43.2 minutes per month. This error budget becomes a spending account for reliability, consumed through planned maintenance windows, feature deployments, infrastructure updates, and unplanned outages.
Modern composite SLOs enhance error budget management by maintaining historical context through configuration changes. Unlike basic implementations where editing components reset the error budget, teams can refine their reliability targets continuously without losing historical data.
For example, during the holiday shopping season, teams might adjust component weights to reflect changed business priorities - giving payment processing accuracy higher precedence over frontend performance metrics. These adjustments can be made without resetting error budgets or losing trending data
When error budget spending accelerates, teams implement reliability measures:
- Pause non-critical deployments
- Scale infrastructure proactively
- Postpone feature launches
- Focus on stability improvements
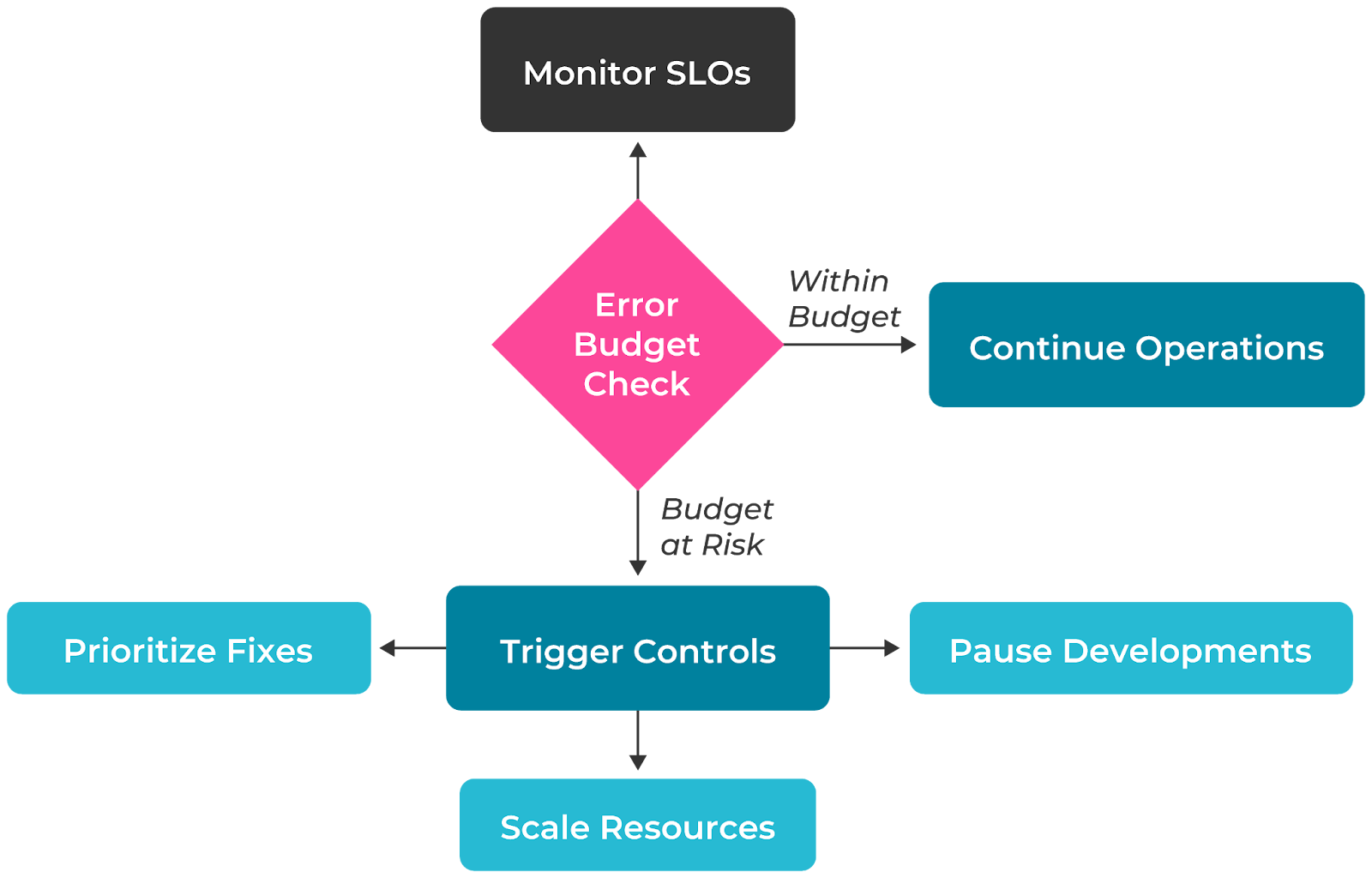
Decisions are based on actual system behavior rather than individual component metrics.
Customer-Facing Reliability Powered by Service-Level Objectives
Service Availability Powered by Service-Level Objectives
Learn More
Establish incident response procedures
When a platform experiences issues, every minute of downtime impacts revenue. Response procedures determine how quickly teams detect, assess, and resolve incidents. These procedures must define who responds, how they communicate, and what actions they take.
Define roles and responsibilities
Response effectiveness depends on role definition and responsibilities. Each incident involves multiple team members working in coordination. The following table captures the essence of the roles and responsibilities that need to be defined.
|
Role |
Primary responsibilities |
Key actions |
|
Incident commander |
Manages the overall incident response and coordinates team efforts |
|
|
Technical lead |
Leads direct technical investigation and resolution |
|
|
Communication lead |
Manages all incident communications |
|
|
Subject matter experts |
Provide domain expertise for specific components |
|
|
Resolution owner |
Takes ownership of implementing and verifying fixes |
|
Creating escalation paths
Incidents follow a severity-based escalation path that determines response timing and team involvement. A rather simple escalation matrix for three severity levels would look like this:
|
Severity |
Impact |
Response time |
Team involvement |
Scenario |
|
SEV1 |
Critical business impact and revenue loss |
Immediate |
Full team response with executive notification |
Complete checkout system failure |
|
SEV2 |
Significant impact and functionality degraded |
Within 1 hour |
Technical lead and relevant SMEs |
Payment processing delays and increased error rates |
|
SEV3 |
Minor impact and non-critical issues |
Within 4 hours |
Local team handles |
Slow product search, minor UI issues |
However, incidents are dynamic events that can escalate rapidly. While initial severity assessment helps mobilize the appropriate response, teams must continuously evaluate the impact of the incident and adjust their response accordingly. Teams should also be able to make judgement calls on the severity of an incident based on the information available rather than being pigeonholed into a rigid definition.
Consider a product search slowdown initially classified as SEV3. The local team begins an investigation, expecting to resolve it within the standard 4-hour window. However, monitoring reveals that the search latency affects the product recommendation engine, impacting the checkout process. As customer complaints increase and revenue metrics show impact, the incident commander escalates the incident to SEV2, bringing in the technical lead and relevant SMEs.
If the issue spreads, affecting core business functions like checkout completion, the incident commander might escalate to SEV1, triggering executive notification and full team response. A progressive escalation like this aligns response efforts with the incident's actual business impact.
The following diagram illustrates this process:
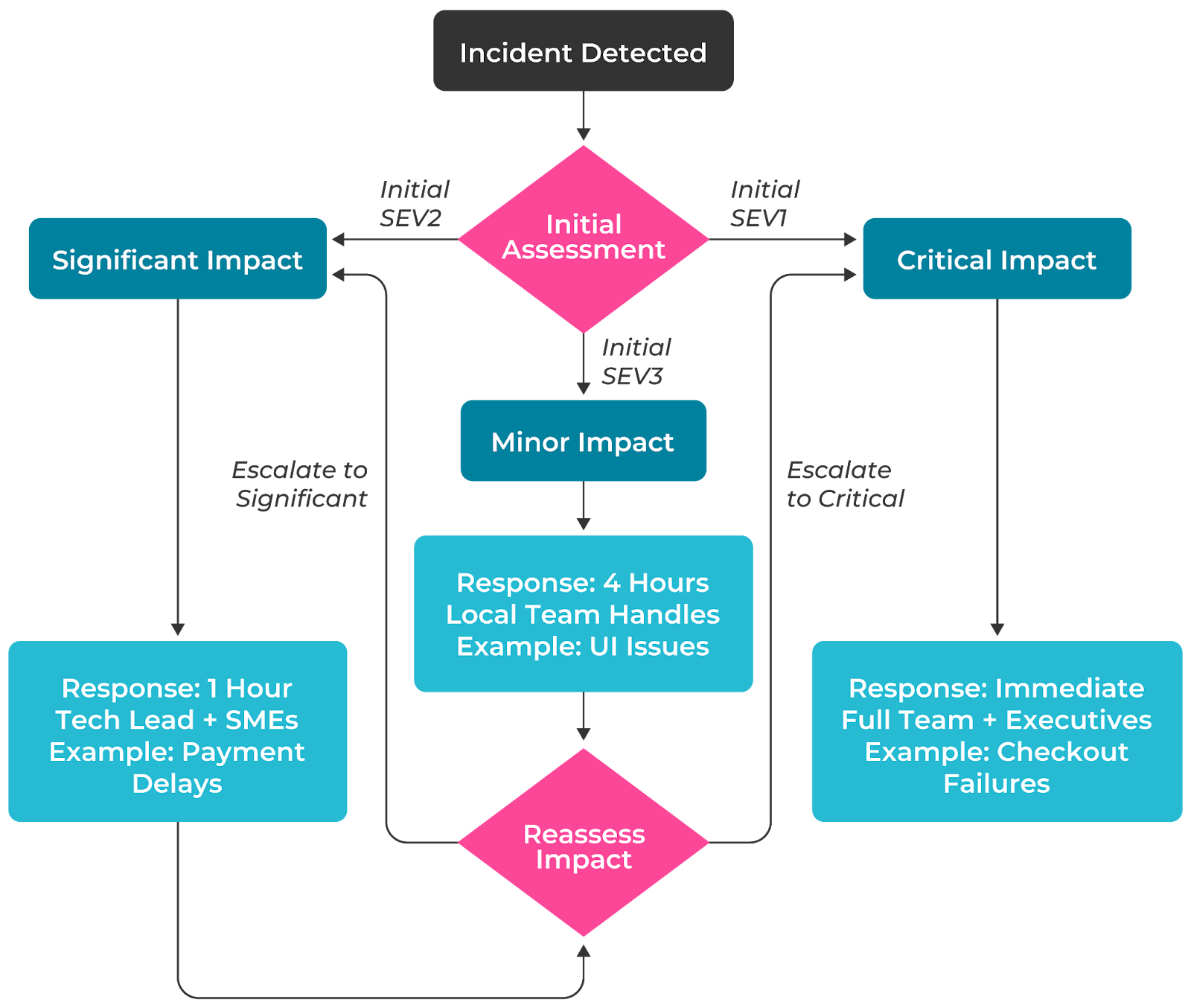
Key escalation triggers include:
- Expanding the scope of affected systems
- Increasing customer impact
- Revenue implications
- Recovery time extending beyond initial estimates
- Dependencies affecting critical services
The incident commander reviews these key factors throughout the response effort and reevaluates severity levels and team engagement as needed. With a flexible approach, operations teams can deploy the necessary resources as their understanding of the incident increases.
Response playbooks
Since the terms playbook and runbook are often used interchangeably, let us first set context around our usage of the terms before we explain the concepts in more detail.
While playbooks and runbooks share similarities, they serve distinct purposes. Playbooks have a broader scope, often involving multiple teams or stakeholders, while runbooks focus on detailed, step-by-step instructions for specific procedures, such as rolling back a deployment.
Playbooks can transform the incident response from desperate scrambling to systematic action-taking when adopted properly. Consider this playbook for a payment system failure; from initial assessment to recovery verification, each milestone comes with a specific set of steps that need to be undertaken, depending on the nature of the problem:
- Initial assessment → Verify payment gateway status → Check database connectivity → Review recent deployments
- Stakeholder communication → Update status page with incident details → Notify customer service teams → Brief executive team if SEV1
- Resolution steps → Follow gateway provider's incident procedures → Document all system changes → Prepare for potential rollback
- Recovery verification → Monitor transaction success rates → Verify customer impact resolution → Document resolution steps
Communication protocols
Communication during incidents follows established patterns that prevent confusion and speed up incident resolution. There are two main types of communication: internal and external.
Internal communications maintain team coordination through dedicated incident response chat rooms, regular status updates based on severity, handoff procedures between teams or team members, and documented decision points.
External communications keep stakeholders informed via regular status updates, support team briefings, executive summaries, and customer notifications.
The industry standard for external communication is using status pages, such as this one: https://status.slack.com/.
Documentation requirements
Every incident should generate documentation that serves current needs and future improvements. Items that typically need to be documented are:
- The timeline of key events
- The actions taken and their results
- Communication logs
- Any system changes that were implemented
This centrally stored documentation provides the foundation for future automation opportunities and post-incident analysis, both of which will be discussed in the upcoming sections of this article.
Last thought: proactive IT incident management with Nobl9
While comprehensive incident management processes and tools form the foundation for handling issues effectively, the shift from reactive to proactive management faces several challenges. Most organizations need help connecting their monitoring data to meaningful reliability metrics and automating responses effectively.
Traditional SLO management tools need help keeping pace as systems become more complex. Teams face increasing challenges integrating data from multiple sources, handling intricate service dependencies, and calculating accurate thresholds. Manual system data analysis can take weeks or months, delaying adjustments to SLO thresholds and potentially midding important patterns.
Nobl9, a founding pioneer of the OpenSLO project, offers a platform designed specifically to address these challenges.
|
Challenge |
Traditional approach |
Nobl9’ solution |
|
Data integration |
Manual correlation across multiple monitoring tools |
A unified platform sitting above existing monitoring systems, collecting data from all resources |
|
Reliability metrics |
Basic uptime and response time thresholds |
Composite SLOs with weighted components reflecting business priorities |
|
Historical analysis |
Weeks of manual data analysis to validate SLO targets |
SLI analyzer and replay features process months of data in minutes in a fast-forward mode |
|
Alert management |
Static thresholds causing alert fatigue |
Dynamic alerting based on error budget consumption |
|
Configuration management |
Manual updates requiring system restarts |
SLOs as code with GitOps workflows |
|
Visibility |
Fragmented views across different views |
Service Health Dashboard and reliability roll-up reports |
Nobl9 transforms this process through unified reliability management. The Service Health Dashboard shows service degradation in context, while error budget tracking helps teams decide on response urgency. Historical analysis through SLI Analyzer reveals if similar patterns preceded past incidents, enabling preventive action. Automated reliability management then closes the loop between detection and response.
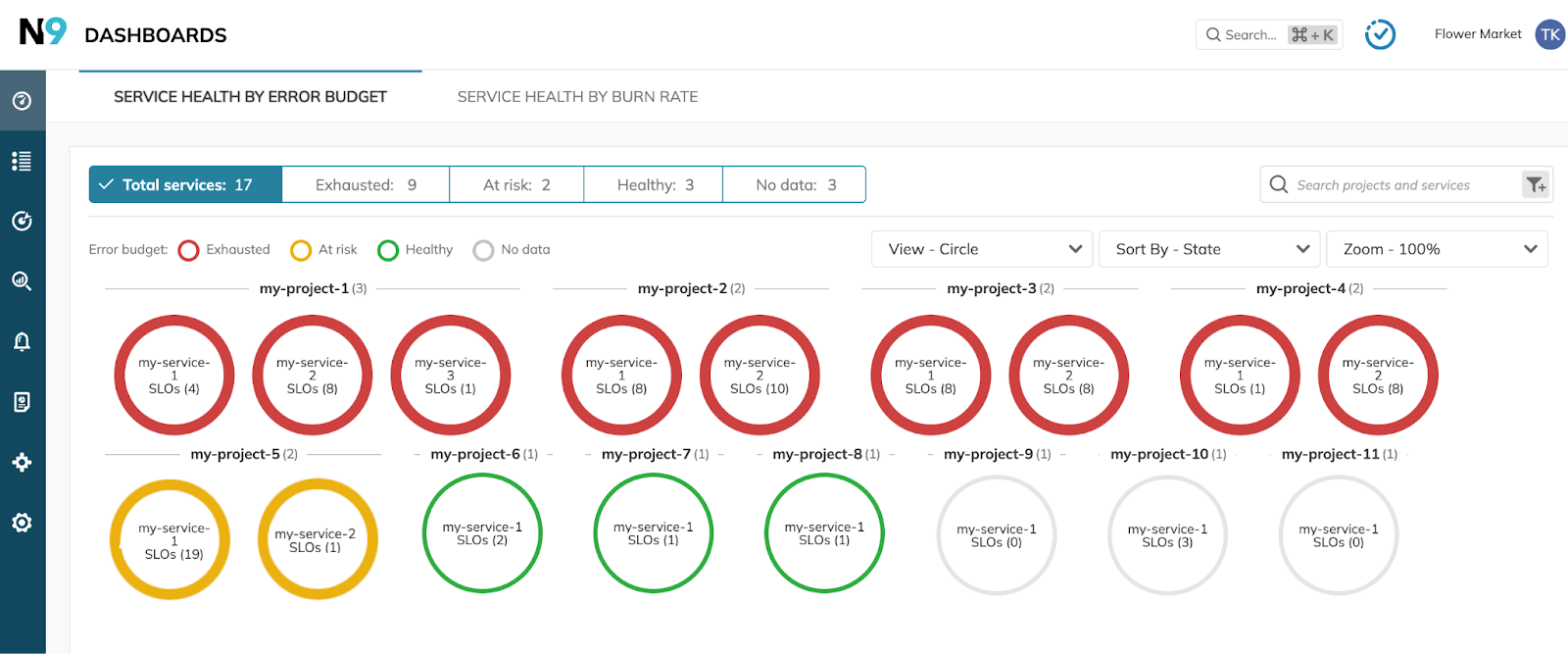
Incident management is often a reactive process, but the transition from being reactive to proactive requires modern SLO tools like Nobl9 to tie infrastructure telemetry with measurable service quality, runbooks, and playbooks for systematic remediation, processes for escalation and post-mortem analysis, and finally, training of the operations and development staff on the tools and processes. The combination helps organizations adopt modern IT incident management techniques applicable to every application, whether running on dedicated servers or Kubernetes clusters.
Navigate Chapters: