
-1.png)


Originally published at DevOps.com on October 30th, 2020
One of the fundamental premises of Software Reliability Engineering is that you should base your reliability goals—i.e., your service level objectives (SLOs)—on the level of service that keeps your customers happy. The problem is, defining what makes your customers happy requires communication between software reliability engineers and product managers (aka business stakeholders), and that can be a challenge. Let’s just say that SREs and Product Managers (PMs) have different goals and speak slightly different languages.
User stories are a great way for PMs to express a customer’s experience and expectations to the engineering team. SREs can then translate the user stories into SLOs in a few simple steps.
It’s not that PMs fail to appreciate the value that SREs bring to the table. Today, in the era of Software-as-a-Service, features like security, reliability and data privacy (which used to be considered “non-functional requirements”) are respected as critical features of the service-product a SaaS company delivers. Modern application users and customers of software services care a lot about data privacy, cybersecurity and uptime, therefore PMs care too. In fact, it’s not uncommon to see these features touted prominently on a company’s website (I saw one today claiming “99.99% uptime for every customer!”), because the folks in marketing know that customers are making purchasing decisions based on whether the company can deliver reliability, speed, security and performance quality. So, yes, PMs do care.
The difficulty lies in the negotiation between the PM and the SRE about the value of providing that level of service and the cost associated with it:
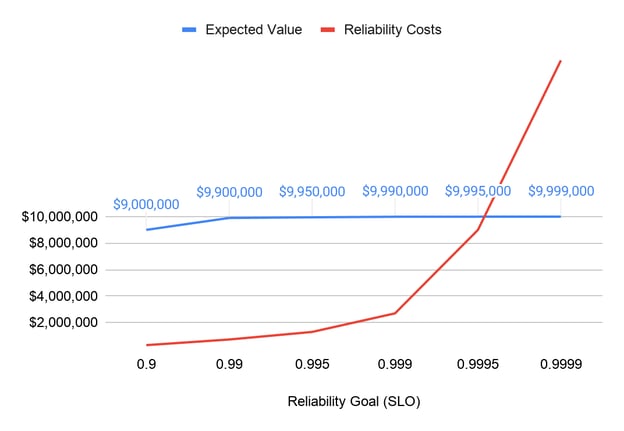
The people and infrastructure costs associated with providing the next level of reliability increase geometrically for a host of reasons, but the expected value to a $10 million business of losing out on that one in 1,000 transactions vs one in 10,000 is only $1,000.
But translating “customer happiness” into actual objectives derived from observable metrics is easier said than done, particularly for companies that are just getting started with SLOs. Let’s face it, all the talk about “nines” can be difficult to conceptualize. Fortunately, there’s an easy way for PMs and SREs to get on the same wavelength.
***Engineers, stop asking your PMs for SLOs! Instead, convert user stories into reliability goals.***
User stories are a great way for PMs to express a customer’s experience and expectations to the engineering team. SREs can then translate the user stories into SLOs in a few simple steps.
So what is a user story?
User stories are narratives that describe how a particular type of user engages with the service. The first-person plotline might go like this: I am this type of person, and this is what I need and expect in order to be happy, and if I’m not happy, this is what it’s going to cost you.
Note: In this user story, we’ve taken the liberty of including empathy for the reliability expectations of the user.
Retail example: I’m a shopper on your online store on Black Friday, and I want to take advantage of your Black Friday sale. I want to log on, peruse your Black Friday deals, pick the products and features I prefer, and make my purchase in just a moment or two. If it takes too long to log on, or if I get hung up in the system, I’ll easily get frustrated and move on to other retailers. I don’t want to miss the deals!
An SRE can take that user story, ask the PM a few questions to gather just a few more critical bits of information, then do some simple math to derive the SLO for your Black Friday.
Ask your PM these questions
To determine the reliability goals for a user story, you need to add three pieces of context:
Step 1 – Identify the top critical user transactions
First, determine the relative priority or criticality of the transaction being successful. Not all transactions are created equally, so we need to understand what kind of transaction we’re talking about here. For example, browsing a catalog page (which could be refreshed if unsuccessful) is different from the shopper’s checkout experience.
Retail example: We have several transactions in a retail business like:
- Inventory catalog search
- Order fulfillment
- Payments processing
- Price & discount
- Checkout experience / shopping cart abandonment
For our example, let’s develop the SLO for payments processing, which is a throughput metric—the total number of transactions a retailer can handle in a given period of time.
Step 2 – Estimate the Volume of Transactions at Various Times
Now that we know the transaction we’re talking about (payment processing throughput), we can estimate the rough volume of transactions or user interactions that will occur in each of those categories, rounded to the closest order of magnitude (see Fermi Estimation). How much of your business happens during this time? Do you have a critical time of day? Do you have a critical season? Do you have a critical day(s) of the year?
The same transaction at a different time may be more or less valuable. Think about an ad playing during the superbowl, or stock prices while the market is open. Or when your CEO is giving a critical customer presentation. Timing matters.
Retail example: Our hypothetical retailer has critical periods in the holiday shopping season and critical days called Black Friday. Typically, 4% of annual business happens during Black Friday weekend, and 16% of annual business happens during the remaining Holiday Season.
Sources: Adobe Analytics estimates that sales for the full weekend (Thanksgiving through Cyber Monday) is 20% of total revenue for the full holiday season. The National Retail Federation says holiday sales were $730.2 Billion, and account for 20% of annual sales.
Step 3 – Calculate the business value of transactions in each circumstance
Finally, we can now understand how the reliability of this transaction affects business outcomes. This could be the risk of lost revenue, or perhaps a brand reputation metric like reduced CSAT. Now you have a pretty clear picture of the business impact of unreliability.
Retail example: If our imaginary retailer has revenue of $10 million, they would make $400,000 of that during Black Friday weekend, and $1.6 million during the rest of the Holiday season. On Black Friday shopping carts are worth $100, $80 during the Holiday Season, and $50 the rest of the time. There are 800 transactions per day on Black Friday, 625 per Holiday Season day, and 488 any other day.
Now that you have this input, you can start to calculate appropriate SLOs based on the value at risk and the cost to meet that reliability goal.

If possible, you can estimate the cost to deliver each level of reliability. Consider not only the cloud computing and direct operational costs, but also the reliability investments in testing, performance, security, chaos engineering, release management, rollback, monitoring, on-call, automation, etc. that would be required to achieve the reliability level at each point. By plotting this cost (at least to the order of magnitude) you can find a break-even point where the value at risk and cost of reliability crossover. This is the business-justifiable SLO for these transactions.

Plot the value-at-risk as a function of value * volume * SLO. The value-at-risk will decline sharply as the reliability is increased; however the cost to achieve this reliability also increases exponentially. It’s simply not worth investing more than that at-risk amount for any given user story, so the SLO determination is clear. Note that the SLO may not be achievable for the team currently, but you have a precise idea of what matters to the business and the break-even point of your reliability investments.
Instead of asking PMs to “speak SRE,” span the communication gap by using the common language of user stories to build business-cogent SLOs.
Share:







Do you want to add something? Leave a comment