
-1.png)

| Author: Alex Nauda
Avg. reading time: 4 minutes
Ah yes, the venerable cloud migration. There’s nothing quite like taking your entire infrastructure, all of your services, backends, frontends, databases, and heaving it, porting it, lifting it onto someone else’s computer. When I think of cloud migrations, what comes to mind first?
Risk
That’s right, migration == risk. What is at risk? From an operations perspective, everything. Reliability. Performance. Cost. It doesn’t matter if you’re doing a lift-and-shift from DC to EC2 or containerization from FreeBSD to GKE: the risk to your customer satisfaction — and your OpEx cost — is very real. Of course, everyone has analyzed the benefits of the migration, and they’ve decided to move forward, but the devil is in the execution! You need a way to protect your customer experience, ensure that cloud services perform as expect (and as advertised), and cost tune your new hosting architecture so that it works well and is cost-efficient within well-defined goals.
Nothing pulls a team together like high-quality shared data pointing to a well-defined objective.
Once you get the system up and running on the new platform, how can you tell that it’s working well for your customers? It certainly isn’t going to run the same way as it did on the old platform (what would be the point if it did?), but it has to run well. What does “run well” even mean in this context? If you’re on the hook for migrating a major product, you’ll face intense pressure while measuring and tuning performance and cost in a changing environment.
I have a technique for you. It’s called a Service Level Objective.
Service Level Objectives (SLOs)
SLOs provide a formal but flexible way of quantifying the performance and reliability of a system and comparing that behavior against performance and reliability goals. SLOs help within a single system and also between various systems or platforms.
SLOs allow you to quantify and codify what “normal” or “expected” behavior means for your system. They enable you to define what it means for a system to be “humming” vs. “knocking” — pull that up into a separate tracking system — and use it for reporting, alerting, and management. Working with application developers and operations experts of the current platform and observing its behavior, you identify key indicators of “good” behavior of the system and set boundaries for those indicators so that you can quantifiably measure observed behavior against the objective. And unlike the blunt SLAs we see in legal contracts; you can define SLOs on broad or narrow service level indicators (SLIs) to measure behaviors that matter to your customers.
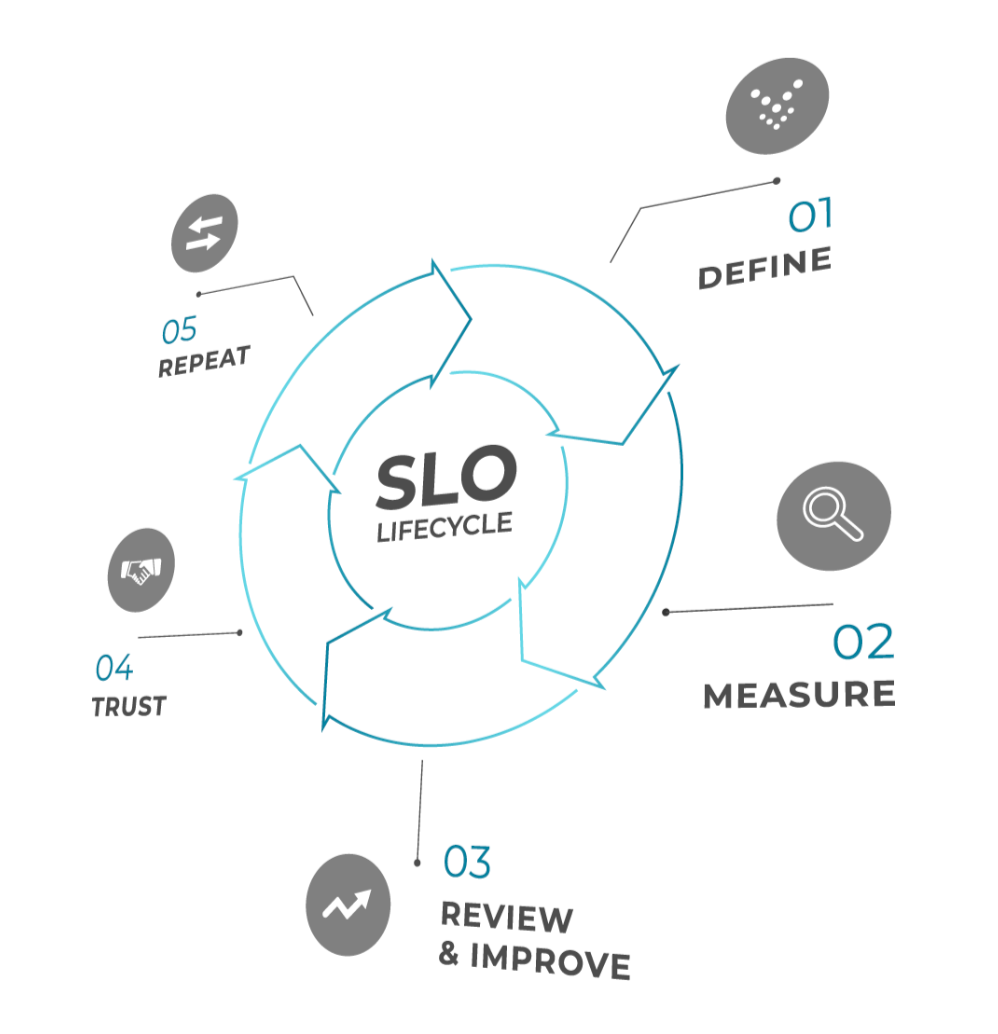
Defining SLOs is typically an iterative process. For a cloud migration, the ideal scenario is that you define SLOs against the pre-migration system and iterate on them to dial them in, focusing on whatever customer and user satisfaction metrics you have available. During migration development, define identical or very similar SLOs on the new platform. Then, through your load testing, stress testing, soak testing, and finally, your post-launch monitoring phases of migration, you have the right stakes in the ground to tell how well the system is working for your customers.
SLO Use Cases in Cloud Migrations
Most migration SLOs fall into one of three categories:
1. Protecting user experience
Define SLOs that closely track real-world experiences of users of the application or product. Try to measure as close to the user as possible. For example, aim to set SLOs on client-side instrumentation, or at least, the client-facing server-side components. Adjust the objectives such that adherence to the SLO means that users are happy. A violation of the Objective should signal user suffering and business impact. Set these SLOs up well ahead of the launch.
Aim to define identical SLOs on the new platform, or make them as similar as possible given the difference between the platforms. We often see that metrics systems, APM, monitoring, logging, etc., differ across migrations (that’s part of the benefit — better observability), so it’s normal for some differences. But suppose you can capture the user experience closely (and assuming your SLO tooling supports a wide variety of metrics, monitoring, and logging systems). In that case, you will find more similarities than differences.
Post-migration, you now have an answer to the constant problem of managing performance and reliability on the new system, right out of the gate.
2. Ensuring 3rd party service levels
If your cloud migration is like mine has been, you are probably adding dependencies on cloud services. At the very least, there will be VMs where there was hardware or a different kind of VMs than before. You may also introduce outside dependencies like cloud object storage, distributed filesystems, virtual block storage, new networking, CDNs, maybe even serverless functions, or container orchestration systems. Not to mention a whole new monitoring and metrics stack from what you had before. These things are external to the application and infrastructure within your control — often in a shared responsibility model. What I’ve needed in this context is a way of ensuring that these new dependencies do what it says on the tin.
Define SLOs on these critical external components, recognizing the performance your application or product demands of them. Keep your service providers honest — trust but verify. Track both uptime and performance, and add in error rates. There’s a reason that cloud engineers utilize defensive coding and resilient architectures. When everything is on the internet, everything goes down or malfunctions at some point.
What you do with the newly gained knowledge if your service providers are not quite holding up their end of the bargain is up to you.
3. Cost goal setting
One critical thing that changes across a DC-to-cloud migration specifically is that cost becomes a monitoring concern. Every good migration plan bakes in a period of monitoring and tuning after launching the migrated system. A typical cloud migration lands on the new platform with some built-in cost headroom for safety. It will likely include a cost tuning phase of 3-6 months before the safety headroom is tuned down to tighter tolerances and, hopefully, to cost efficiency goals.
With SLO measurement tooling, you can set aspirational cost goals as failing SLOs. Let them run in the red and make them visible to development, operations, and management stakeholders. This technique gives you a quantitative assessment of how you’re tracking against the hosting cost goal. You should be able to maintain a daily cost objective in most cloud systems.
Nothing pulls a team together like high-quality shared data pointing to a well-defined objective.
Impact
At the end of a migration project, the ultimate measure of success is not just arriving at the full implementation but keeping customers, users, and stakeholders happy across the very risky relocation of a complex system. I hope you consider using SLOs to ensure that happiness. I wish I had SLOs for every one of my cloud migrations. At Nobl9, we aspire to build the best and most flexible SLO tooling on the market, helping SREs, developers, and operations teams provide the most reliable systems that they can. We hope you will give it a try in your next migration.
Share:







Do you want to add something? Leave a comment