
-1.png)


This article will get a bit deeper into how to turn service level objectives (SLOs) into a tool for balancing investments in new features and in improving the reliability of your software.
Error budgets can be thought of as a conceptual model for understanding acceptable risk in your services. You want to provide a highly reliable service to customers, but because of diminishing returns of marginal error rate reduction, you aren’t setting your SLOs impossibly high. We call it a “budget” because your organization can allocate (or spend) it and track its current balance. It can also be manufactured like a fiat currency (which can actually devalue reliability, more on that later). Depending on your budget refresh schedule, your acceptable error rate, your current balance, and your rate of burn, you can rationalize many competing priorities across a large scale software organization.
We need to attach a form of consequence to the error budget that has a real effect on the allocation of resources within the organization.
📊 Turn Your Error Budget Policy into Action
A well-defined error budget policy helps balance reliability with innovation. Learn how Nobl9 enables teams to track, enforce, and optimize error budgets for better decision-making.
🎯 Book a DemoBut first, back to the basics – how do we calculate an error budget in the first place? Whatever SLO you set below 100% implies an “acceptable” error rate for your service. Just take 100 minus your SLO and that’s your error budget. So if you have a “three nines” service, your acceptable errors (and therefore your error budget) for the SLO is .1%. You could also describe this as 1 error per 1,000 service requests. If you are striving for “four nines,” your budget becomes 1 error per 10,000 service requests. Generally speaking, the larger the budget the more freedom you have to change the system (which introduces risks) but the impact is users won’t be able to rely on the service as much. On the other hand, minimizing an error budget means you don’t have much wiggle room for mistakes or interruptions to service and you will have to put a lot more thought and energy into how you manage risks associated with changes in your system.
Before we get into calculating the current balance and burn rate of budget, we need to answer a fundamental question, which is what makes an error budget real? Just like the currency metaphor we are following, error budgets only have value if we collectively believe they have value. If no one takes an error budget seriously, their behavior won’t be influenced by it and the entire premise of the system breaks down. So we need to attach a form of consequence to the error budget that has a real effect on the allocation of resources within the organization. Since we are trying to create a cultural shift to a team that correctly balances reliability and features, we need to notice when we are leaning too far one way or the other and correct back to center.
Therefore, an error budget policy simply states what a team must do when they deplete their error budget. The general remedy is easy: if you blew your error budget, go focus on improving reliability. This may be enough of a policy to get most of the benefit, although teams have created more sophisticated policies with various thresholds and rules of escalation.
On the other end of the spectrum, once a service is consistently exceeding its SLO (and leaving Error Budget in the bank) it means the team can take on more change risk, or possibly increase the SLO to tighten the tolerance for error. Taking on more risk might mean a faster pace of release, reclaiming spare computing capacity, adding more testing in production with riskier experiments, or delaying some reliability ideas in favor of features.
The elegance of this approach is that it allows the team to self-police and truly derive their decisions around reliability based on serving customers. Remember that in order to have proper service level objectives, they need to track with user happiness and should be strongly correlated with external signals. So the error budget isn’t a magic talisman that we are divining the balance from; Error Budgets are funded directly by our ability to satisfy customers!
Error Budget Policy Practices
There are a few areas of defining Error Budgets that have practical tradeoffs. Let’s go through a few areas that need some thought and try to cut out some of the guesswork based on real-world practices.
Budget Refresh Schedule
Your budget is allocated to a window of time and is usually apportioned on a “use it or lose it” basis, meaning you can’t carry forward unused budget to a future period. This is to prevent hoarding budget for a few months (or years) and suffering a catastrophic outage that just brings you up to even. Generally, a rolling 4-week window works well and aligns with a timeframe that both engineers and business stakeholders can understand.
Rolling windows are preferable to calendar-based refresh schedules because it smooths out permissible error across a consistent time frame. Although there may be cases when you want to take a step back and look at error budget management practices over a wider timespan aligned to a calendar, looking at the broader organization over a particular quarter or year.
Acceptable Error Rate
We discussed that error budgets are derived from SLOs, but the inverse is also true: an SLO is achieved based on the actual rate of errors, and the decision to allow those errors is what defines the error budget and the SLO. This is perhaps an easier way to conceptualize reliability than uptime, where you count the number of minutes the system is “up.” If your system has multiple active replicas in different regions, you may be able to claim 100% uptime without issue. Meanwhile, if more than 1 in 1,000 service requests (on a timescale of milliseconds) fail than you haven’t even achieved three nines (99.9%).
You may want to also prioritize different types of traffic, set up availability zones, and create synthetic load. Each of these may have an impact on the error rate and the acceptability of errors in given user cohorts. All this to say that setting up complex error budgets requires some flexibility and is a bit of an art since the goal is to have a high affinity to business priorities in the real world, not set up some abstraction that confuses the map for the territory.
The good news is that you can create freedom for your teams to each fine-tune their acceptable error rate per SLO. While there is local freedom, you can achieve global consistency in language and policy across teams. If you adopt SLOs and error budgets, you essentially reduce all user happiness and service metrics to a fraction of 1, and these become comparable across domains, no matter the complexity in each individual measurement.
Error Budget Burn Rate
If you are trying to get proactive in reliability, then understanding burn rates is really important. Since you have defined the acceptable error rate for a given service, it doesn’t really do anyone any good to sound the alarm if you stay within that error rate. On the other hand, you would probably like a trustworthy early warning system to avoid the consequences of depleting error budget for your team. While it might serve your team right to shift to reliability work from spending error budget, it would be preferable to avoid that situation. Once error budgets are trusted, these can become the primary source of alerting and can reduce noisy false positives (where no action was required) considerably.
The Error Budget burn rate takes into account 3 factors: 1) the current error rate, 2) the remaining error budget, 3) the time until the error budget is refreshed. The goal of the calculation is to understand if the current burn rate (which may be elevated due to a novel problem) will deplete the remaining error budget before it is refreshed. If we stay in this situation for long, we won’t have any error budget left. So smart teams set up a trigger so they are alerted via slack or perhaps even an on-call page when this condition persists for more than a short period of time.
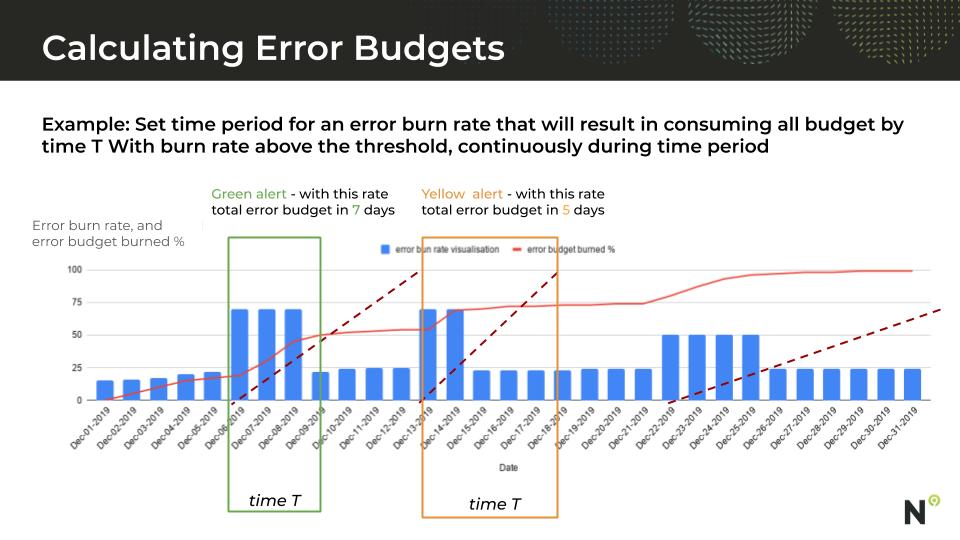
The beauty of this approach to alerting is that it takes user experience and the cumulative effect of errors into account, no matter what type of service is being measured. You can easily bypass noisy alerts from spurious errors, small blips of network outages, or a bad release that was quickly rolled back. Instead, you are alerted when you are trending toward consequences (e.g., violating the error budget policy), which is exactly what a team wants to know about. Suddenly we are playing for real money.
Error Budget Policy Enforcement
As we said earlier, error budget policies have to have consequences for them to be taken seriously. This is not to say there can’t be exceptions to the rule. Some organizations set blanket policies to mediate the obvious situations. For example, if two teams burn error together and the outage is determined to be root caused in Team A, then we might allow by policy that Team B’s error budget is topped up. The same rule could be used if a major vendor (such as a cloud provider) occurs without an obvious reliability mitigation.
Error budgets are what change metrics into action, but only if they are collectively understood and taken seriously.
The toughest situation comes when a team is forced into a reliability-work-only state by depleting their error budget, but a senior stakeholder wants to overturn the policy in favor of a feature release. It may surprise you that this is actually OK, as long as management understands the implications. Rather than throwing out the policies, there is usually a compromise made that might involve temporarily relaxing the SLO and a clearly articulated plan for reliability improvement (and putting other feature work on hold) after this particular deliverable is made.
Another approach is to commandeer development resources from other teams (essentially putting their feature work on hold) to pay down the technical debt and make up for the error budget. There are lots of ways to negotiate around the budget, but the fact that the budgets are derived directly from customer experience and the organization’s desire to serve customers tends to bear much more weight on decisions than data selectively sourced to make an argument about one-off reliability problems. It invades the culture and changes the conversation to be all about balancing the tradeoff. While the policy might sound like bureaucracy, it is the opposite of politics that decide investment decisions based on the influence of certain team members.
Conclusion
Error budgets are where service level objectives start to become real. They are what change metrics into action, but only if they are collectively understood and taken seriously. Realizing quantitatively that users are not getting the experience you thought was good enough (let alone ideal) can have a dramatic push on an organization. It exposes true beliefs and priorities.
If you are a senior manager of a reasonably sized technical team, your role is not to be the arbiter priorities, micromanaging every feature and reliability plan of every team (unless you’re into that). Instead, cultivate a culture of quantifying customer happiness and your current ability to meet their needs, and proactively balancing reliability investments right when they’re needed. Let your feature requests sit for another week or quarter, and get reliability under control. If you do this across your teams you will see a positive culture shift in short order. Managing an error budget creates wealth, one happy user at a time.
Image credit: Sarah Killian on Unsplash
Share:







Do you want to add something? Leave a comment