






.png?width=1200&height=628&name=Building%20Reliable%20E-commerce%20Experiences%20(24).png)
.png?width=1200&height=628&name=Building%20Reliable%20E-commerce%20Experiences%20(22).png)
.png?width=1200&height=628&name=Building%20Reliable%20E-commerce%20Experiences%20(19).png)

The world of technology has never been as dependent as it is now on data, and this shift is causing a sea change. There was a time when companies could thrive while giving little thought to keeping their technology stack up to date, and creating and managing technical debt was not a significant concern. Companies might have had a monolith application that ran on-prem and deployed only once or twice a year, and not experienced customer churn. They might have been able to function normally with no monitoring solution, or just a basic in-house tool. But those days are long gone.
Companies today all have a large amount of data to work with. The question is, what should we do with it?
Making sense of the data we have is a major part of the advancement of technology, and we at Nobl9 understand the importance of machine learning in this area. Nobl9 provides a first-class enterprise solution for managing SLOs from different data sources, and Fourteen33 is a close partner of ours that focuses on consultation around the cloud, AI, and automation. Over the past few weeks, we've worked together on a study on how we can align SLOs with machine learning practices, in order to shine a light on how companies can be more efficient and effective with the data we have. We focused on answering one important question: Why does machine learning need SLOs to be successful?
To provide that answer, we considered a real-life example that many of us have experienced. We looked into a rideshare application similar to Uber and Lyft, where the customer requests a ride, and once the request is sent the algorithm predicts how long it will take for the ride to arrive. Such applications use a data model to perform a set of calculations and define the wait time for the rider. However, there are many factors that could affect the accuracy of this result, such as a sudden accident that requires a route change, or hitting every single red light on the way to the rider. Hence, the data model uses machine learning techniques to constantly evaluate how it’s performing. When it reaches a point where the predictions are no longer sufficiently accurate and the performance is not acceptable, the data model needs to be retrained.
In this scenario, if we were to use a traditional monitoring solution that alerts the engineers when the performance has dropped under a certain threshold, it might not tell the whole story and so will not necessarily be impactful—performance might have dropped due to one ride being stuck for hours behind an accident. This is where SLOs come into play!
Nobl9 helped the Fourteen33 team to optimize the performance of the data model and automate the process around retraining it. Taking an SLO approach, we allocated an error budget to the data model’s performance and, based on the consumption of that budget, we introduced certain actions. In this case, the model can make a specified number of incorrect predictions within a defined time frame. If it consumes the whole error budget, this will automatically trigger the retraining of the model. However, if it consumes some of the budget but does not exhaust it within that time frame, then no action is required. Another action that could be taken here is to trigger an alert that notifies the engineers if they are getting close to consuming the entire budget, or if there is a sudden increase in the burn rate.
For this use case, we considered two different SLOs:
- Technical metric: How far off the prediction is from the average standard deviation
- Business metric: How many times the prediction is wrong
The following image shows these two SLOs in Nobl9 in a 1-hour window:
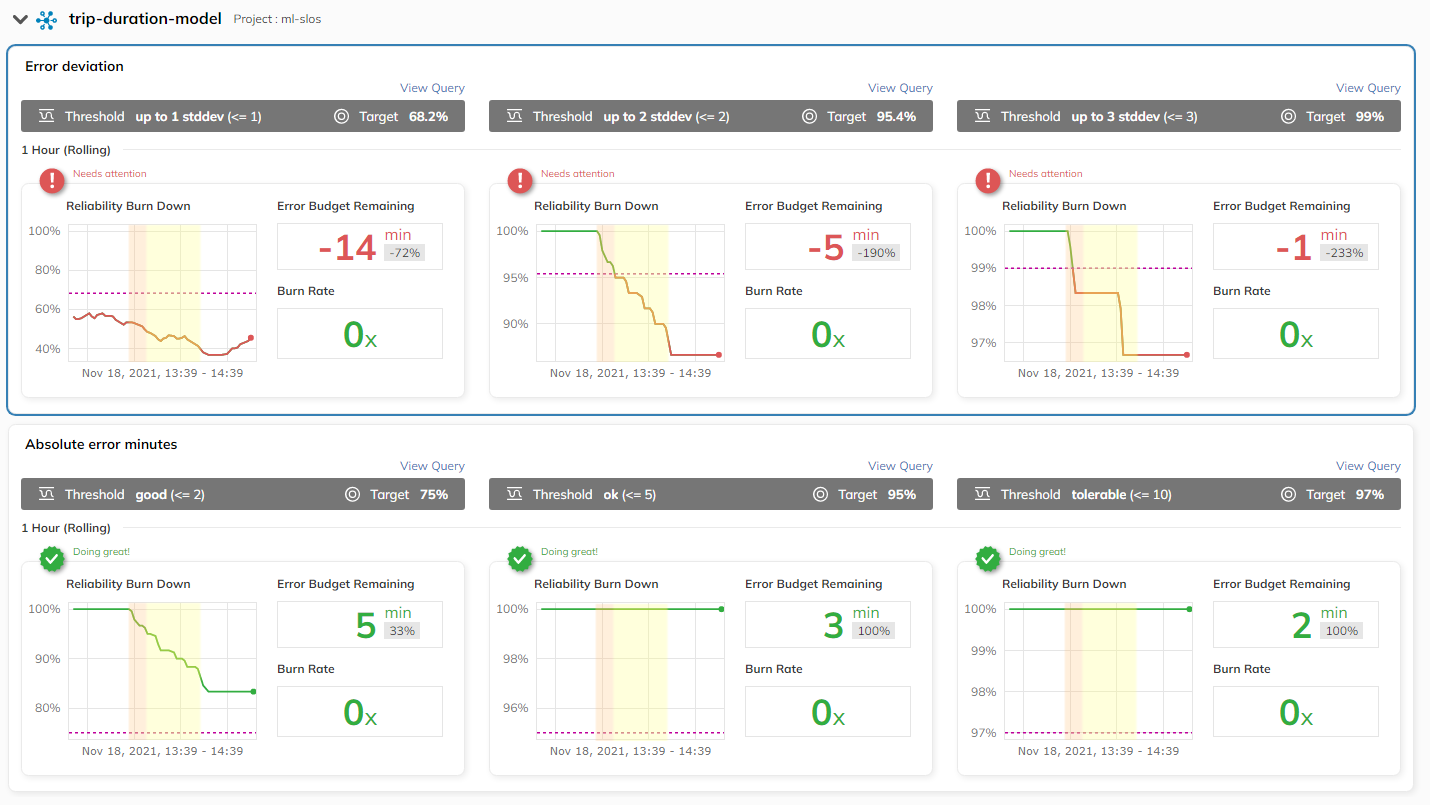
The top row contains an error deviation indicator (the technical metric). The SLO thresholds indicate the magnitude of the difference from the average error value (within 1, 2, or 3 standard deviations). The average error and standard deviation are calculated each time the model is (re)trained. Monitoring the error deviation is crucial for the team maintaining the ML model, as it allows them to see when the model’s performance is deteriorating before the business metrics get worse. If the deteriorating trend in the deviation distribution continues, Nobl9 sends an alert indicating that the model should be retrained.
The area highlighted in red marks the time between the triggering event that impacted the performance of the model (the moment of change in the input data) and the raising of an alert. In our use case, this could be something like the start of road works in the city center, making trips last longer than before. The area highlighted in yellow marks the time lapse between the alert and model redeployment.
The business metric (absolute error minutes) is presented in the second row. This set of charts indicates how often the prediction is inaccurate and the size of the error. For example, if the algorithm predicts that the car will arrive in 5 minutes and the actual arrival time is 4 minutes or 6 minutes, then we have 1 absolute error minute. The business cares about these factors because it connects the technical issue to customer experience and behavior. This SLO shows the accuracy of the model, and there is budget allocated to the amount and level of inaccuracy that is tolerable.
The first target for error deviation (in the top-right box) is set to 68.2%, which is an acceptable threshold for the model. Even though the model error rate at the beginning is below the threshold, we can see that the predictions were not off by more than 2 minutes (the business metric), which is acceptable. Thus, even though we had a performance issue that caused the model to be retrained, the business metric did not consume all of its error budget.
Looking at the 2-hour view of the same SLOs, you can see that the burn rates plateau and then start recovering, which indicates that retraining the model on new data led to the errors becoming smaller and fewer and the metrics returning to the standard level.
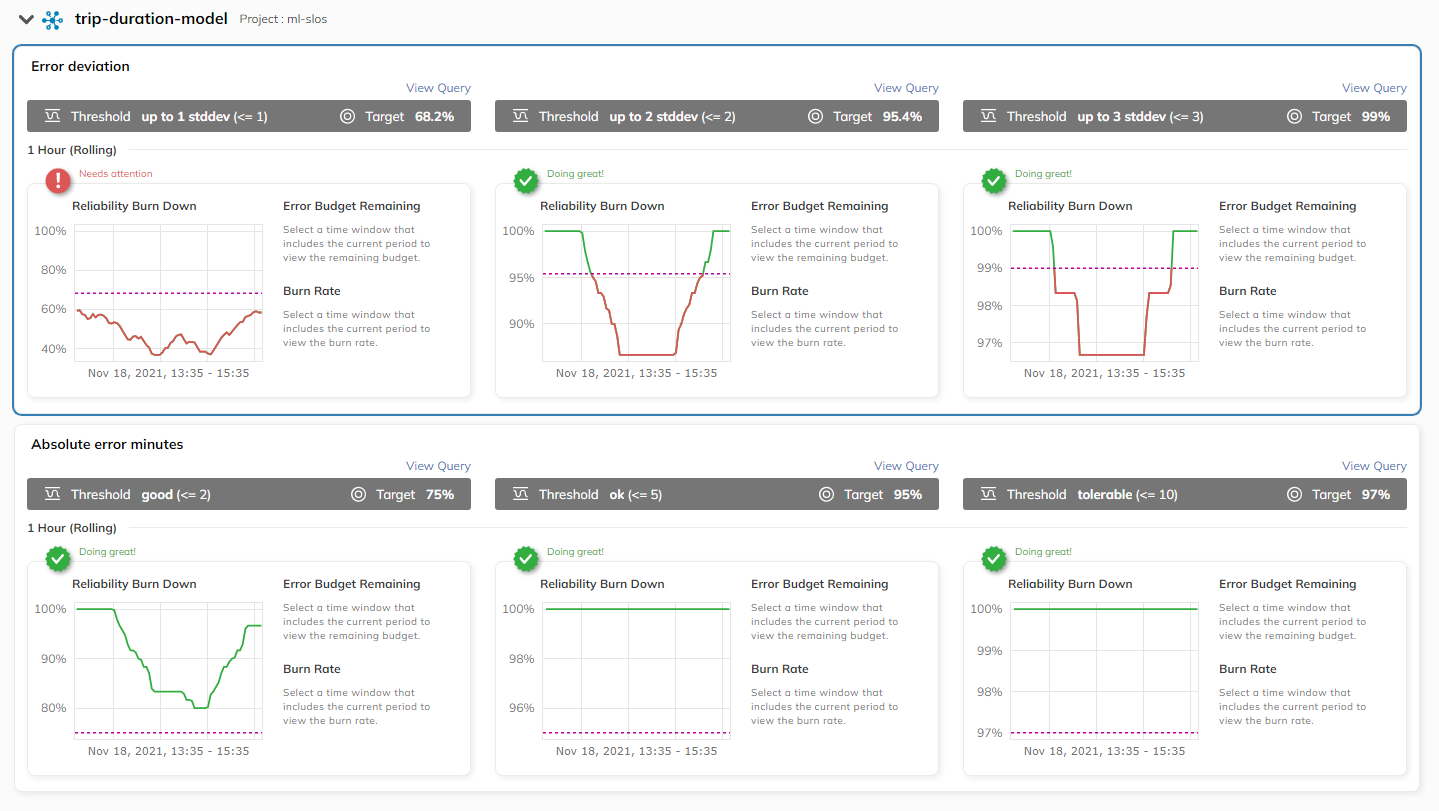
In summary, we created two SLOs and allocated an error budget to the performance of the data model. Each SLO had two alert policies attached to it:
- The first one informs the team that the burn rate is high, which is an indicator of an immediate issue that could have been caused by external factors. Nobl9 has many integrations with incident management systems, and we used Slack notifications for this.
- The second one, for when the error budget is exhausted, uses the Nobl9 Webhook integration to automatically trigger retraining of the data model.
This study showed how SLOs and machine learning can be used in collaboration to automate the process of improving data models. We learned that by capturing the correct metric that represents the performance of the data model, we can reduce the need for direct monitoring and use SLO information to trigger a warning or automatically retrain the model when needed.
The Fourteen33 team is ready to partner with you to help you with this process, and Nobl9 now offers a free tier of their platform so you can get started today at no cost. If you’re an existing Nobl9 user you can see how you can take your SLOs to the next level by applying them to complex algorithms and MLOps use cases you may be currently measuring manually.
And don’t forget to register for SLOconf, our virtual attend-while-you-work event dedicated to SLOs.
Let’s SLO!
Share:







Do you want to add something? Leave a comment