
-1.png)

Table of Contents
Like this article?
Subscribe to our Linkedin Newsletter to receive more educational content
Subscribe nowService level objective (SLO)
Service level objectives (SLOs) are a set of targets, often expressed in percentages, defined by service providers and internal teams. They help ensure the expected performance and reliability delivered to users of a service. They are crucial in monitoring the service quality you offer and indicating whether you are meeting user expectations or are at risk of breaching agreements with the stakeholders.
For example, a team can define an SLO that specifies that an application must be available 99.5% of the time over one year. Another SLO could state that 97% of web page load time from users should be less than 3 seconds within one month. These measurable targets help align teams on what represents an acceptable performance and provide a benchmark for tracking progress over time.
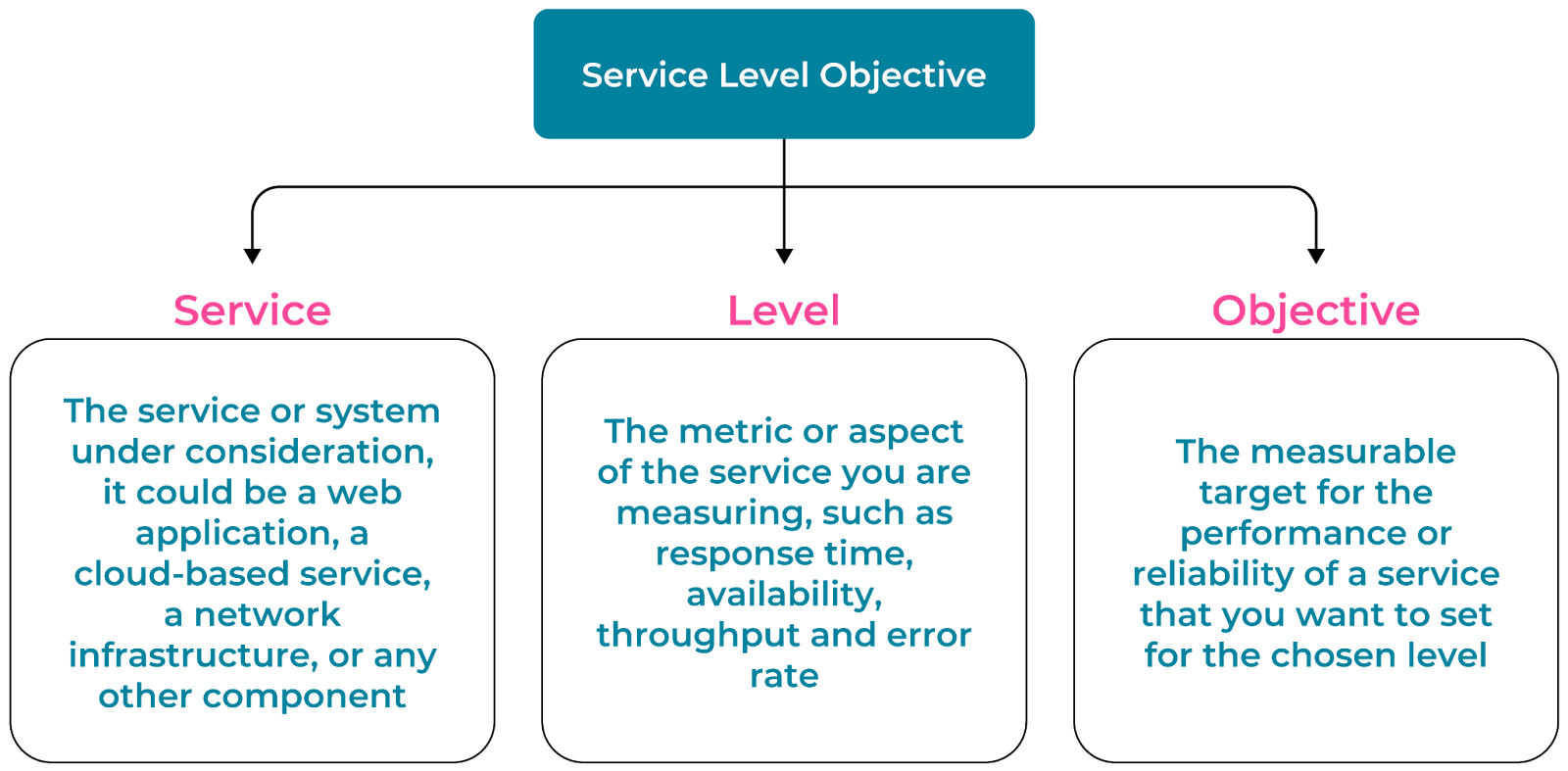
Service level objectives have three components: Service, Level, and Objective
Service level agreement (SLA)
A service level agreement (SLA) is a written contract between a service provider and a customer, created by the legal and business teams, that defines the expectations and commitments between both sides and the consequences for not meeting the agreed SLA.
While SLAs and SLOs are both reliability targets, they differ in purpose. SLAs typically have a legal remedy associated with them, such as monetary credits. Conversely, SLOs are internal targets that define measurable performance metrics. In another context, SLOs focus on technical performance goals, while SLAs provide the legal framework that formalizes those objectives.
In order to meet an SLA, teams should generally use an SLO target that is higher. For example, an SLA might include a term for 99.0% availability, while the service provider targets an SLO of 99.5% to provide a buffer before breaching the SLA. An easy way to tell the difference between an SLO and an SLA is to ask yourself, “What happens if the objective is unmet?” If there is no legal consequence, you are talking about an SLO.
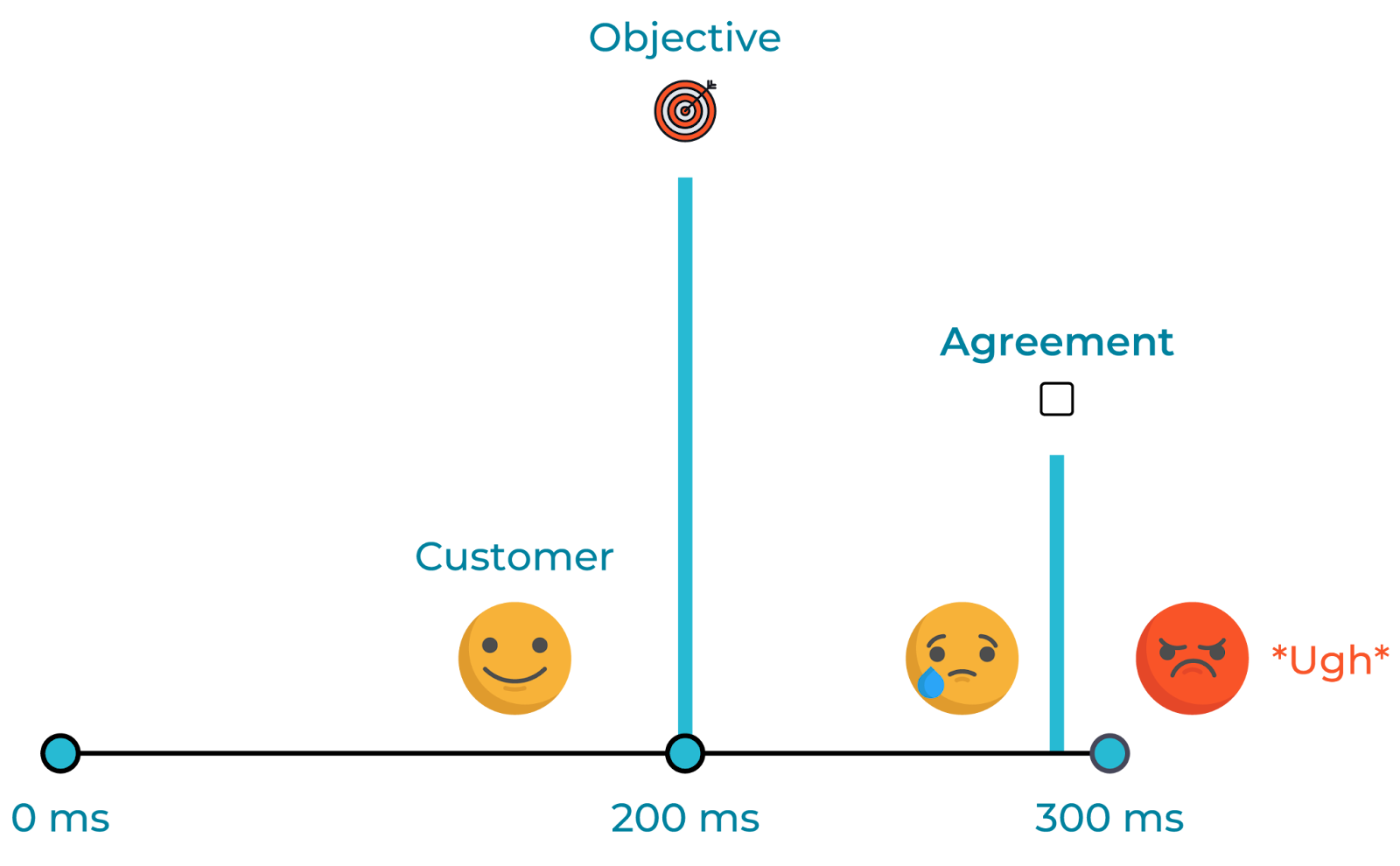
SLA is a more relaxed target than SLO (Source)
Customer-Facing Reliability Powered by Service-Level Objectives
Service Availability Powered by Service-Level Objectives
Learn More
Integrate with your existing monitoring tools to create simple and composite SLOs

Rely on patented algorithms to calculate accurate and trustworthy SLOs

Fast forward historical data to define accurate SLOs and SLIs in minutes
Burn rate
The burn rate is the rate at which the error budget is consumed. A 1x burn rate means that the error budget will last for the time window and be consumed at the end of it. A burn rate higher than 1x indicates that the error budget is burnt too quickly, which would result in breaching the SLO.
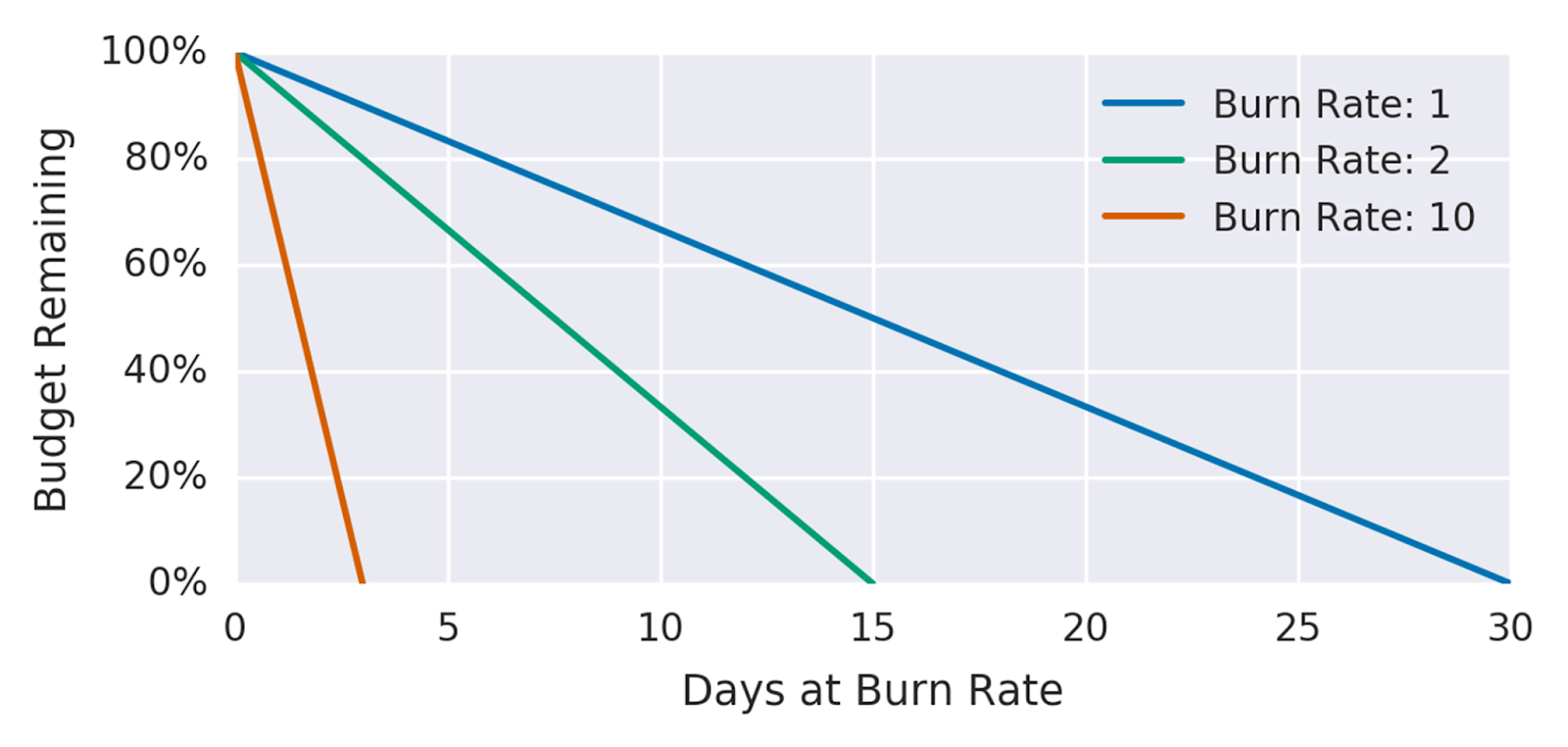
A burn rate higher than 1x will consume the error budget before the time window ends. (Source)
To calculate the burn rate, you need to be able to calculate the SLI's error rate during a specific time window.
Error rate = Number of Failed Events / Total Number of Events * 100
Imagine you have a web application with 50 failed login attempts from a total of 2000 attempts during the last week.
Error rate = 50 / 2000 * 100 = 2.5%
Once you have calculated the error rate, you will be able to calculate the burn rate of your SLO with this formula:
Burn rate = Error rate in a time window / (100 – SLO%)
For the previous example, if the availability SLO of the web application is 95%:
Burn rate = 2.5 / (100 – 95) = 0.5 %
Customer-Facing Reliability Powered by Service-Level Objectives
Service Availability Powered by Service-Level Objectives
Learn More
Alerting on SLOs
An alert on SLO measures and notifies how much deviation from the SLO has occurred, ensuring that notifications are triggered well before the error budget is exhausted. This helps teams take preventive actions rather than reacting after the SLO has been violated.
According to Google's SRE books, there are some key factors to evaluate an SLO alerting system:
- Precision: The proportion of failure events detected. A higher rate indicates that every alert corresponds to an event.
- Recall: The percentage of failure events were detected. A higher percentage ensures failure events are not missed.
- Detection time: How quickly an alert was triggered after an issue starts. Short detection times minimize the consumption of the error budget and enable faster response.
- Reset time: How quickly an alert triggers if there's an issue and how quickly an alert clears after the issue is resolved, which helps the operations team focus on new incidents.
Alerting on the remaining error budget
Error budget-based alerts track the amount of the error budget consumed and the amount remaining. This method helps clarify how much room remains before an SLO breach.
There are two methods to alert on the remaining error budget:
- Alert on the remaining percentage: For example, an alert is triggered when the service has only 20% of its error budget left.
- Alert on the remaining duration: An alert will trigger when only 90 minutes of allowable downtime remain in the SLO window.
To calculate the error budget remaining, you must first calculate the error budget consumed:
Consumed Error Budget = Number of failed events / Number of the allowed to-fail events (Error budget) * 100
Remaining Error Budget = 100 % - Consumed Error Budget
Let’s think about an online store that promises an SLO of 99.5% availability over a 30-day time window. From the historical data, we can expect this online store to handle 100,000 order requests over the 30-day period, which translated into an error budget of 500 orders. During the month, 50 order requests failed to process.
Error Budget Consumed = 50 / 500 * 100 = 10 %
Remaining Error Budget = 100 % - 10 % = 90 %
Alerting on the burn rate
Alerting on burn rates helps to notify teams about failure incidents that cause an error budget to be consumed before the end of the SLO time window.
Some may think they can ignore alerting and check the burn rate from time to time, but that’s not right; even the low and steady burn rates, which might go unnoticed, can significantly consume the error budget in the long term of the time window.
To calculate the burn rate, we use this formula:
Burn rate = (Budget consumed × Compliance period) / Alerting window
For example, if a team decides that consuming 10% of the error budget (20 out of 200 allowed failures) in one hour is critical and should be alerted on, they can calculate the burn rate for a 30-day compliance period as follows:
Burn rate = 10% × 720 hrs / 1 hr = 72
The challenge here would be:
This burn rate alert will never alert if the error rate is lower than the burn rate of 72. A burn rate of 25 will still consume all the budget in 8 hours.
Time to consume the budget = Error Budget / Burn rate per hour = 200 / 25 = 8 hours
Multiple burn rate alerts
Multiple burn rate alerts ensure that the low and steady burn rates that will consume the error budget in the long term are detected and notified.
For example, we can alert in these cases:
- If the burn rate over the last 1 hour consumes 2% of the budget
- if the burn rate for the last 6 hours consumes 5% of the budget
- if the burn rate for the last 3 days consumes 10% of the budget
The challenge would be:
The long reset time for the alert. For example, in the last alert, you would wait 3 days to know that 10% of your error budget had already been consumed. After the team applied their code changes, you would wait another 3 days to evaluate the result. It will also require some mechanism of alert suppression so as to avoid alerts firing multiple times for the same events.
Best practice: Multi-window, multiple-burn rate alerts
This is the recommended alerting method in which an alert is configured on two different alerting windows: a short one and a long one; the shorter time window. This type of alert is for sure more complex than the previous methods. Still, it ensures that the internal team is notified in both cases when there’s a critical issue with a high burn rate and also notified when there is a steady and slow burn rate that might exhaust the burn rate in the long term.
For example, we can alert in these cases:
- If the burn rate over the last 1 hour consumes 2% of the budget and the burn rate over the last 5 minutes consumes 2% of the budget
- if the burn rate for the last 6 hours consumes 5% of the budget and the burn rate for the last 30 minutes consumes 5% of the budget
- if the burn rate for the last 3 days consumes 10% of the budget and the burn rate for the last 6 hours consumes 10% of the budget
Alert fatigue
Alert fatigue happens when an excessive number of alerts, often including false positives, are triggered, overwhelming the operations team. This leads to critical alerts being missed or delayed. False positives are alerts that were flagged to be exhausting the SLO but, after further analysis, were found not to be.
Symptom-based alert over a caused-based alert
In addition to multi-windows and multi-burn alerts, there are two common types of alerts teams should consider: cause-based and symptom-based.
- Cause-based alerts: Focus on specific technical measurements. For example, you can alert your on-call team when the CPU usage over a database exceeds 90%, but that high CPU usage may not be meaningful to the user and might not affect your SLO budget at all. This will cause alert fatigue.
- Symptom-based alerts: Focus on specific symptoms, like latency. For example, you can alert your on-call team when 98% of the database queries take more than 500ms over the last 5 minutes. This is an incident that requires attention as it will breach the SLO.
Alert cooldown
Another way to overcome alert fatigue is the cooldown feature. Nobl9 provides this out-of-the-box feature to users to ensure that alerts are not repeatedly triggered for the same issue in a short period of time. Applying a cooldown period allows your team time to resolve the incident without being overwhelmed by duplicate alerts.
It is a parameter you define while creating an alert policy that establishes the amount of time that must pass to change the status of an alert from the okay status to an alert being triggered or from an active alert to the resolved status.
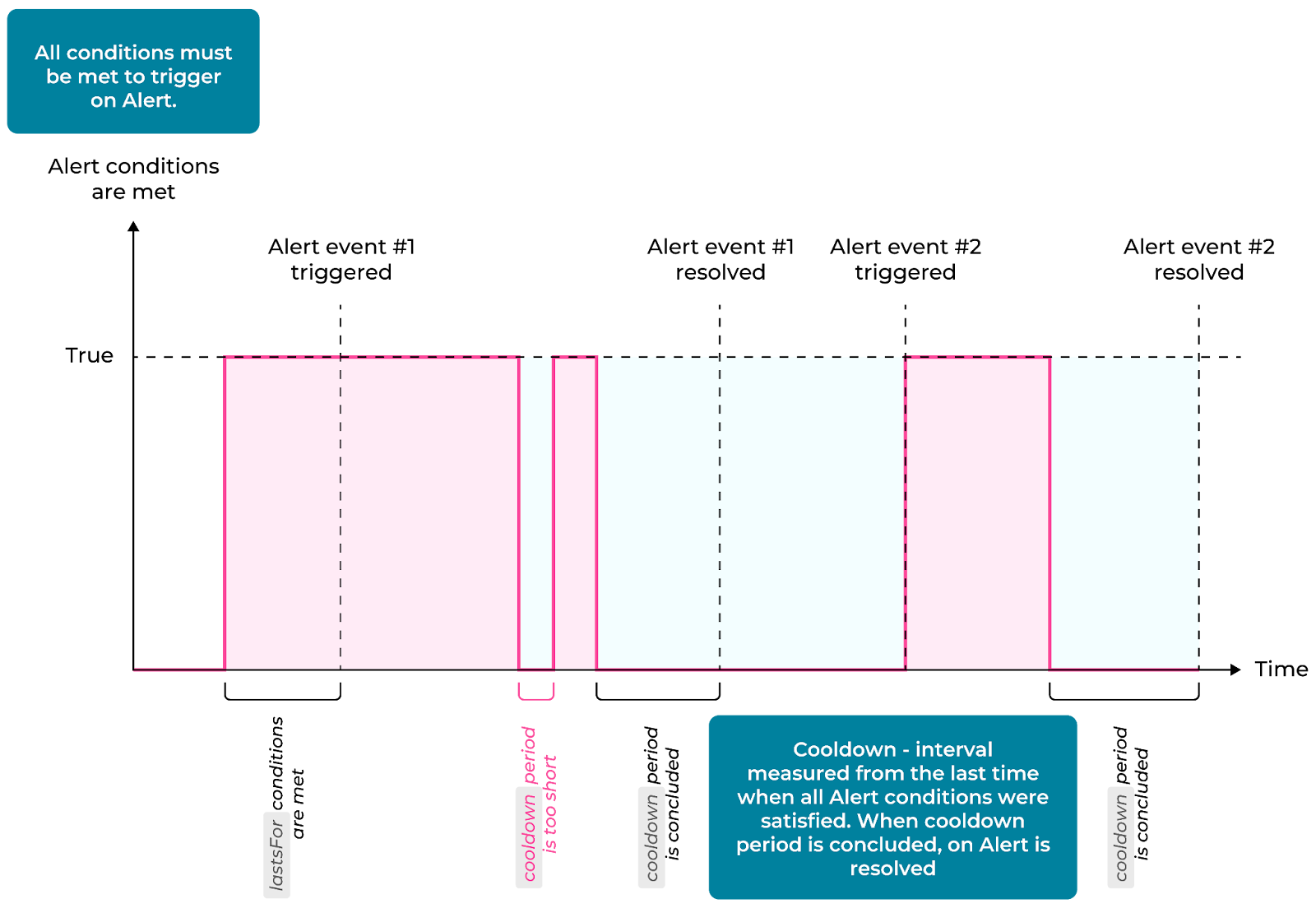
A lifecycle of an alert in Noble9 configured with a cooldown time. (Source)
Seven proven SLO best practices
The six service-level objective best practices below can help teams optimize their monitoring and alerting strategy.
1. Focus on the user experience
SLOs should focus on users' expectations and what matters to them. Most users care about the application or service functioning as expected; they won't care if your CPU utilization is over 70%. So, always resist the temptation to add many SLOs for metrics that don't relate.
- Define the user journey: define the critical services of your application or website that the users interact with, such as the front-end service or the cart service
- Base SLIs on user journeys: Pick up the SLI metrics related to the journey you defined. For example, select metrics like uptime, latency, or error rate.
- Align the SLO target with the customer's expectations: set targets based on the user's satisfaction levels.
2. Use meaningful and measurable metrics
Creating an effective SLO requires meaningful and measurable SLI metrics that accurately reflect service performance and the user experience. Here are the best practices to follow when defining these metrics:
- Define a clear SLI: SLI metrics shouldn't use generic terms like "I want a reliable or fast service." Instead, teams should use specific metrics, such as a service with 99.5% availability up time or a service with no more than 3 seconds response time.
- Keep it simple: Limit the number of SLIs to the top-priority ones that impact the user's journey most.
- Use a monitoring tool: Accurate measurement and collection of data points requires a monitoring and logging system.
3. Set realistic targets
It’s essential to be realistic when setting an SLO to avoid setting expectations that your system can’t meet. Setting an achievable target ensures customer satisfaction and prevents SLO breaching. Here are three tactics to help teams get it right:
- Avoid aggressive targets: setting a 100% SLO for uptime or performance is unrealistic and leads to burnout and SLO violation. Instead, set a target that you can consistently achieve.
- Take into account external dependencies: If your service or application depends on a third-party service, this may also affect your SLO, so always leave room in your SLO for incidents you have no hand in.
4. Involve technical teams and stakeholders
Setting effective SLOs requires communication across different internal teams and involving the stakeholders to ensure that the expectations are achievable and satisfying for everyone.
- Collaborate with cross-functional teams: Engage developers, operations, product managers, and business stakeholders to ensure the expectations are achievable and satisfying for everyone.
- Get mutual agreement and collect feedback: Involve all the internal teams in the SLO setting process and collect feedback after that process. Also, ensure all agree on the expected targets to ensure alignment and avoid future conflicts.
5. Choosing the convenient time window
Choosing the right time window requires context and can significantly affect how service-level objectives influence business outcomes. Here is a breakdown of the benefits of short vs. long time windows:
- Short windows allow teams to make decisions quickly. If an SLO was violated in the previous week, immediate action, such as bug fixes, can help prevent further violations in the following weeks. Use short windows if you have an application that requires tight feedback loops. For example, in an e-commerce platform, daily SLOs should monitor operations to track critical metrics such as website uptime, page load times, and order processing success rate.
- Long windows are useful for strategic decisions. For example, imagine you are deciding whether to migrate your infrastructure to a new cloud provider. It must be a well-informed decision that requires a large amount of data and a long time window to evaluate effectively.
6. Create SLAs based on SLOs
It’s important not to get mistaken between Service Level Objectives (SLOs) and Service Level Agreements (SLAs). A good SLA relies on a well-defined and accurate SLO. SLOs define the internal goals for service performance, while SLAs define the minimum accepted level of performance promised to the customer. Here are some recommendations when creating SLAs:
- Guide the SLA with the SLO target: Define the commitment target in the SLA to be more relaxed than the defined SLO target; for example, if your SLO specified an uptime of 99.5%, the SLA should be slightly lower, maybe 99%, to allow for unexpected incidents.
- Define clear penalties: The SLA contract must indicate the consequence of breaching the SLA target. This can be a refund, a penalty fee, or contract termination.
- Use simple language: Avoid using complex terminology to define the contract terms so that all parties can understand what they are agreeing to.
7. Revisit, review, and update regularly
Feedback loops and continuous improvement are essential to a robust monitoring strategy. Teams should encourage empiricism and improvement with practices such as:
- Consider SLOs as a dynamic process: adjust and update periodically to align with the evolving users and business needs.
- Use historical data: Analyze the past and current SLI values to determine how an SLO target can be updated to be realistic and achievable.
- Manage the factors contributing to error budgets: External factors such as third-party outages and maintenance windows can skew error budgets. These anomalies can exaggerate failure rates and give an inaccurate representation of service reliability. For example, Nobl9 allows users to control the factors contributing to the error budget to circumvent this problem.
- Tighten or loosen SLOs: Based on historical performance data, check your SLOs. If they are consistently met, consider tightening them; if they are too challenging, try relaxing them to allow more error budget.
Recovering historical data with Nobl9 Replay
What happens if your SLI data is lost or your monitoring system corrupts?
Nobl9 introduced the Replay feature to address this common monitoring problem. Replay allows users to retrieve historical SLI data and recalculate SLO error budgets without worrying about data loss or gaps in SLI data that will affect the calculation of the SLO. This is equivalent to fast-forwarding historical data through the SLO logic to evaluate the results. Replaying the stored historical data allows teams to assess different SLO configurations and the design of the ideal SLO without waiting weeks to observe the live SLI metrics and try different configuration permutations sequentially.
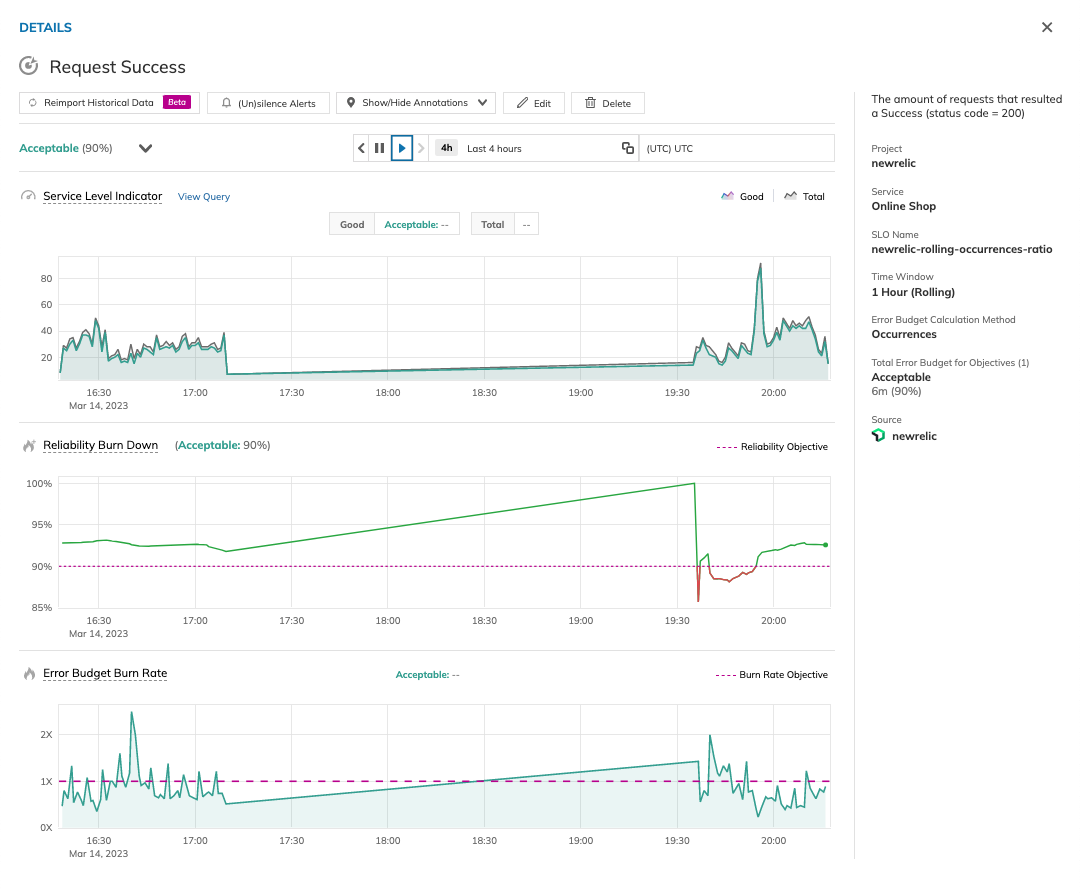
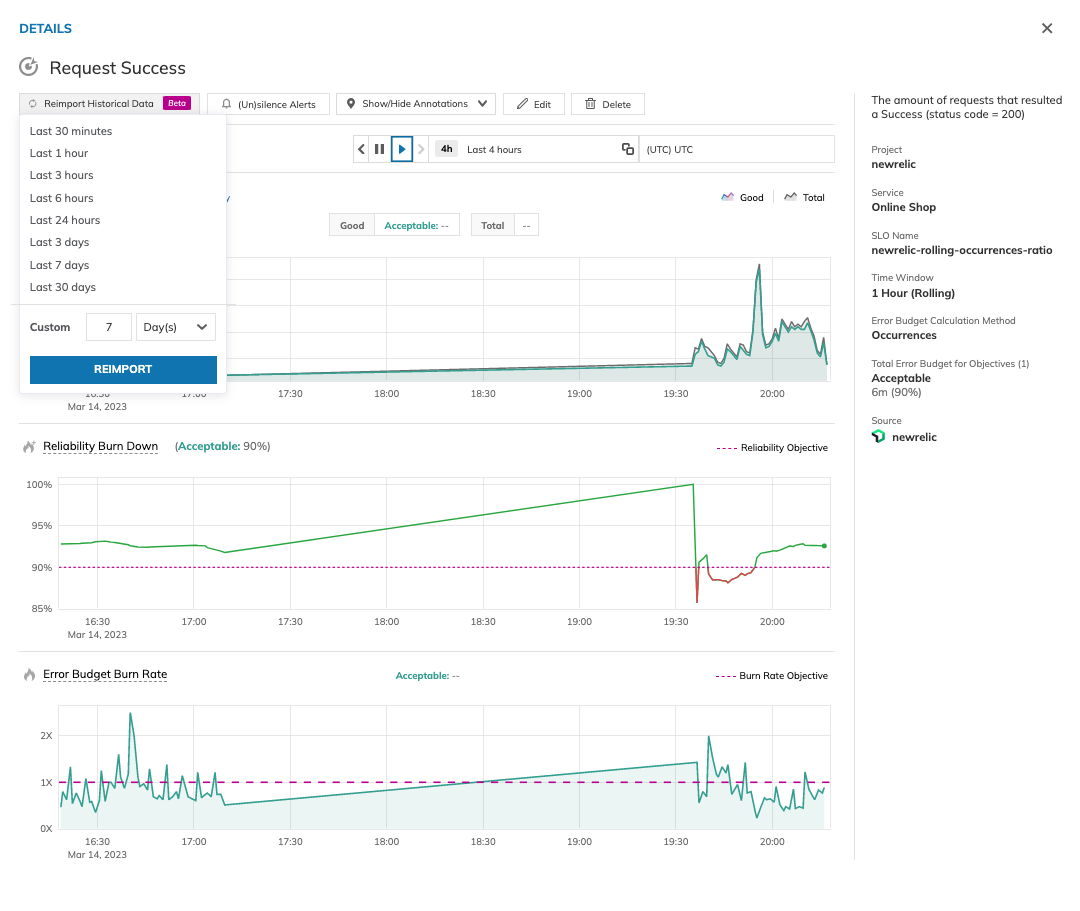
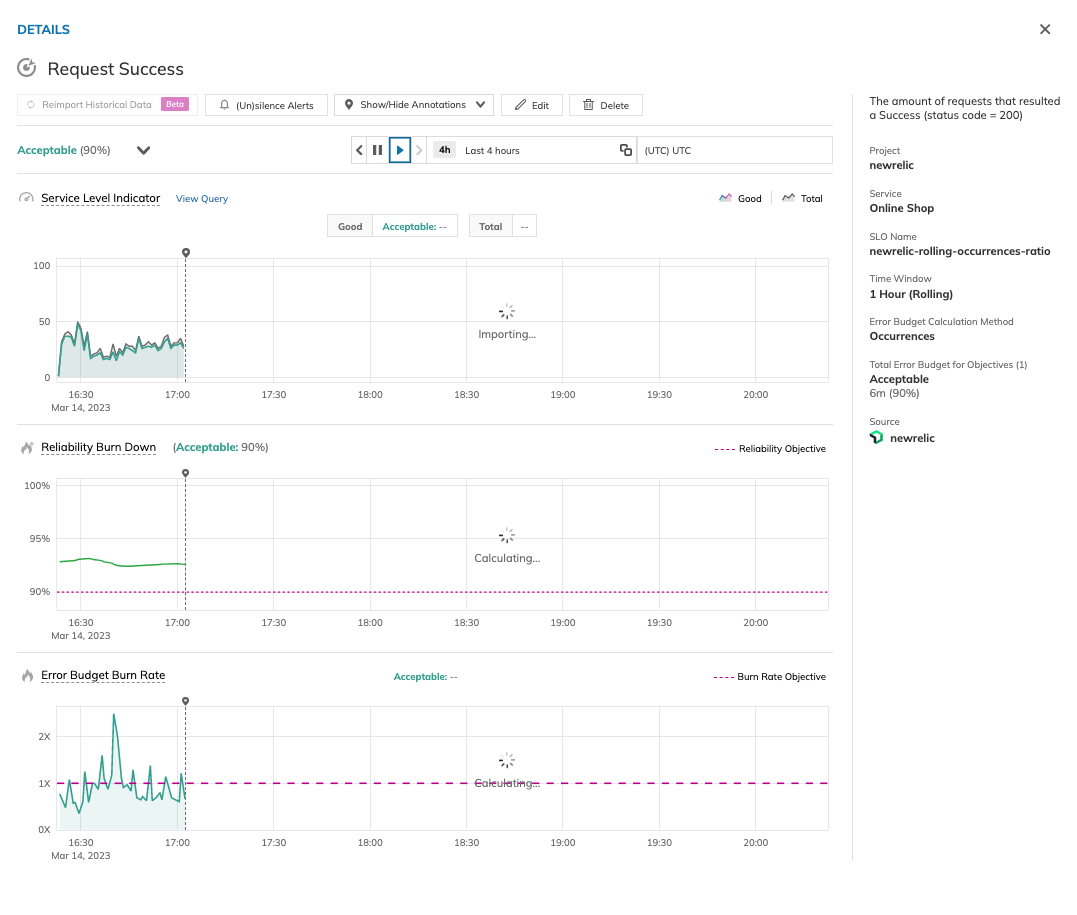
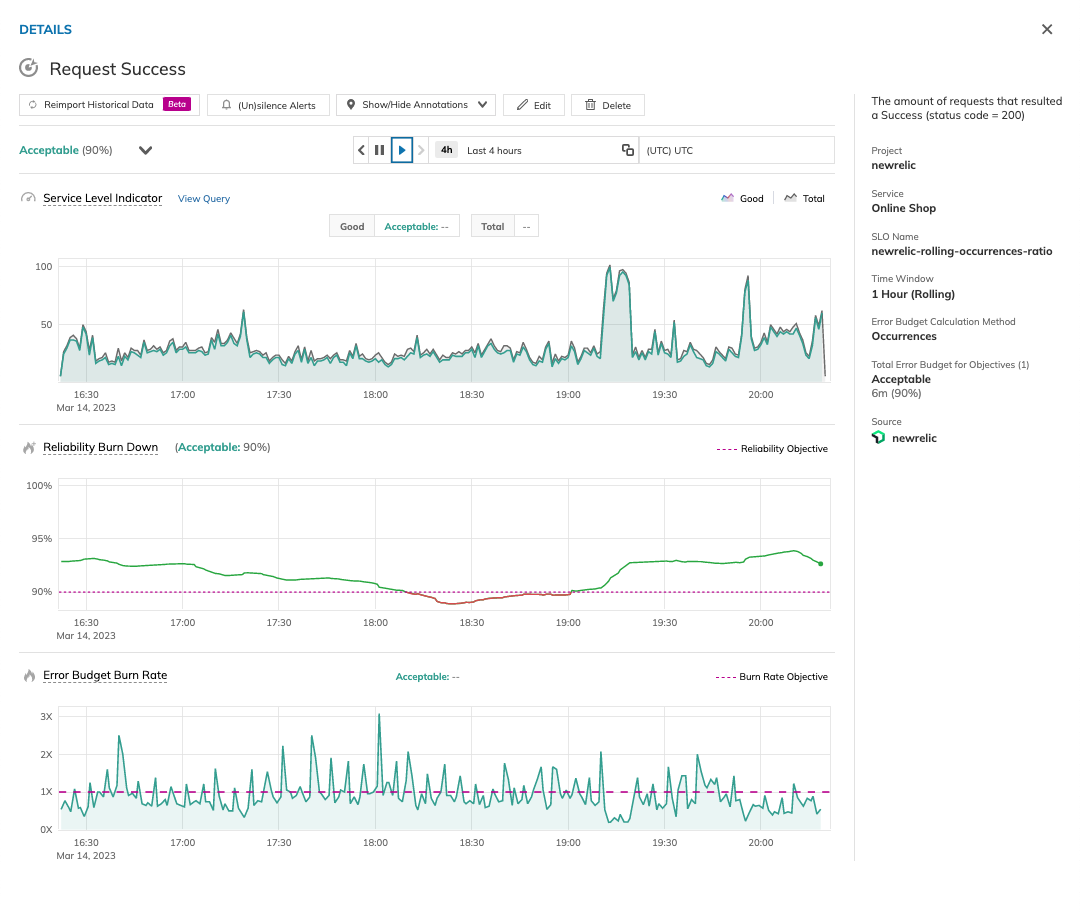
Test and adjust the SLOs with the Nobl9 SLI Analyzer
To set a reliable and realistic target for your SLO, you will need to review your system's historical performance. Nobl9 introduced the SLI Analyzer feature, which processes up to 30 days of historical data and lets you review the outcome of your SLO before you implement it. This avoids the risk of unrealistic targets and saves the time you would spend on trial and error.
You can change the targets from the interface and tweak them to see the resulting error budgets and error budget burndown. Once your analysis is complete and you have determined your target, you can directly create a new SLO from the analysis interface.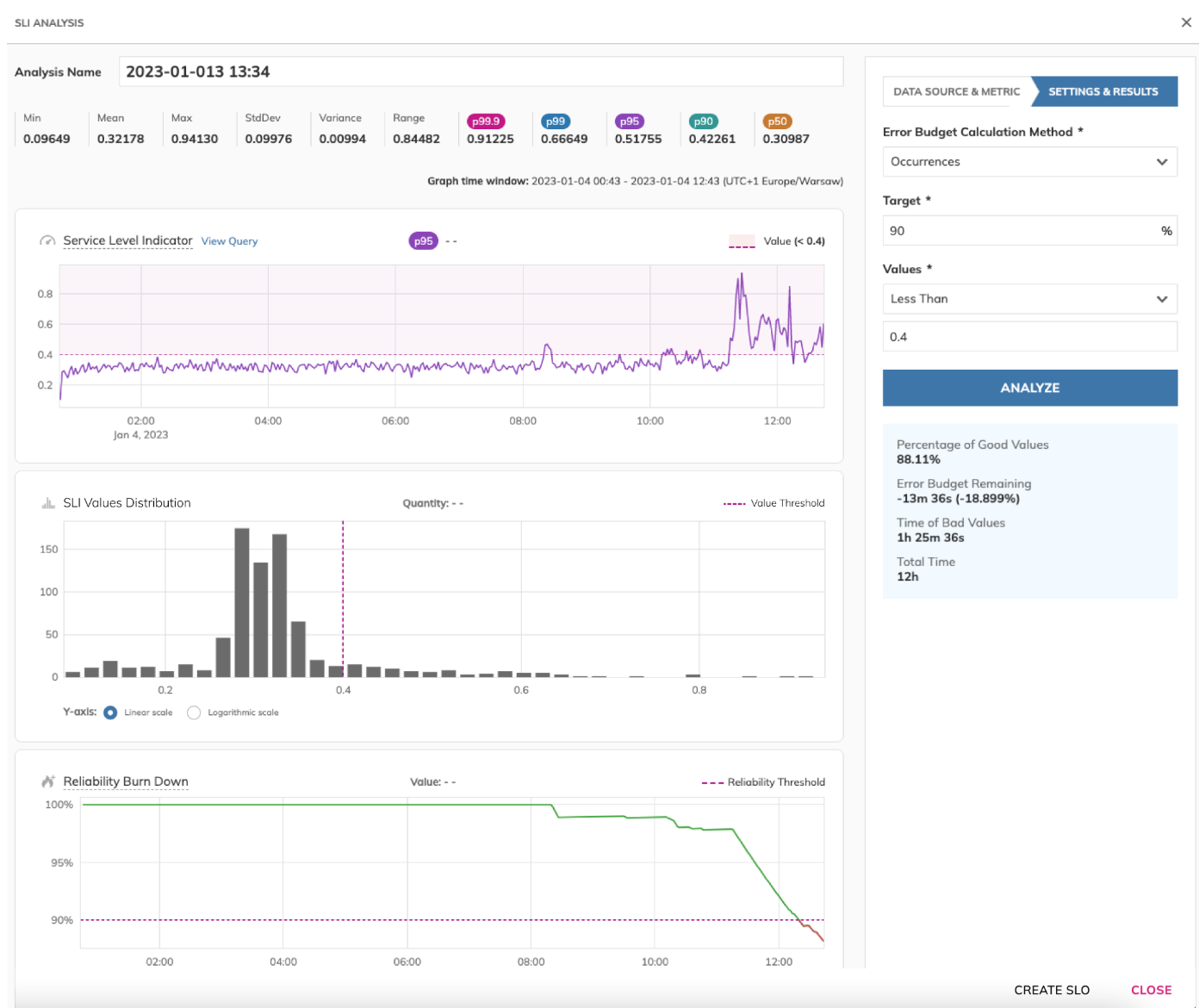
Navigate Chapters: