
-1.png)

What is five 9s availability?
Nines are a unit of measurement used to describe the reliability of a system or process. The term “five 9s” refers to a reliability level of 99.999%. This means that the system or process in question is operational 99.999% of the time. In the context of availability, this is often referred to as “perfect uptime” because it’s so close to 100%. To put it into perspective, five 9s uptime would mean that a system could be down for no more than 5 minutes and 15 seconds in a year or about 6 seconds per week.
Do you really need five 9s availability?
Call it what you will: Always On, Six Sigma, high availability, or five 9s. Management wants you to deliver a service as close to perfection as possible—but there is a downside to high availability. In a world where applications are delivered over public networks, the physics of achieving the goal of just five minutes of downtime per year makes this an expensive long shot at best.
How do you actually reach this level of availability when you need it?
And how do you know when you don’t need it?
This post answers those questions and explains how your teams can develop a common understanding of availability that focuses on the customer experience, not arbitrary availability metrics.
🚀 Join top companies optimizing their SLOs with Nobl9!
See how our platform helps teams achieve reliability and maximize ROI. Experience Nobl9 in action and discover the benefits for yourself!
👉 Book a DemoWhat does it take to keep customers happy?
Today, most people expect IT services to just work. We are happier when applications, websites, and services are always available than when “the website (or server or network) is down.” A corollary more to the point: Unavailable apps equals unhappy customers—customers can’t use a service that’s down. Even small glitches in an available service can be extremely problematic; what good is it if I can reach my bank’s app but check depositing won’t work?
Rather than aiming for too much of a good thing, you should prioritize your services and choose carefully the level of availability each service needs.
Availability is the very definition of competitive advantage in cloud computing. Some cloud providers even say the availability of their network is the most important facet of their services. Enterprise infrastructure teams make the same argument. That’s why you hear so many people throwing around the term “five 9s” these days.
Customers should be quite happy with five 9s availability, so setting that as a goal makes good sense. . . or does it? Does it really take five 9s to keep your customers delighted with your service, especially when you look at their journey through your application?
The question is an important one, for one very simple reason: cost.

Delivering five 9s availability is expensive. Each nine added to your availability percentage costs your organization an order of magnitude more. For a customer-facing service to be five 9s available, all the supporting services have to have even higher levels of availability. You can think of it this way: every nine adds another zero to the end of your total cost of ownership (people and infrastructure). Is it worth it?
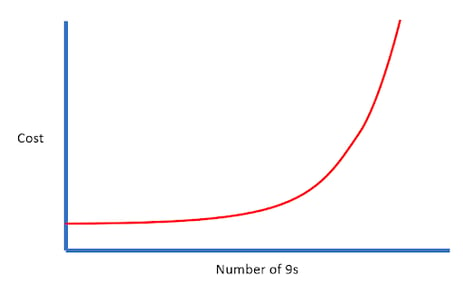
Probably not, especially since the more realistic outcome of trying to achieve five 9s is failure. You may think you are prepared to deliver a high-availability service, but, in reality, availability at that level would just be a lucky coincidence.
For most of your services, the chances are customers won’t notice the difference between three or four 9s and five 9s. In fact, three 9s is an impressive result that takes thoughtful planning and investment. In the majority of cases, trying to achieve more than that isn’t fiscally justified: it will cost you too much money and too much time, and you’ll be wasting resources where they aren’t needed. However, most businesses do have a minority of cases where aiming for extremely high availability is warranted. Focus your investment on those critical services.
🚀 Optimize Your Service Reliability with Nobl9
Struggling to balance high availability with cost-effectiveness? Discover how Nobl9's platform empowers teams to define, monitor, and optimize Service Level Objectives (SLOs), achieving optimal reliability without unnecessary expenses.
🎯 Schedule a DemoHow is five 9s availability connected to server uptime?
The term “five 9s availability” is often used to describe how often a system, a server, or a service is available. The "9s" refers to the percentage of time that the system or service is expected to be operational. For example, "five 9s" availability would mean that the system or service had events that were successful 99.999% of the time over a given period.
Five 9s availability is often used as a goal or target for systems, servers, and services that need to be highly available. However, achieving five 9s availability can be difficult and expensive. As a result, many organizations settle for less than five 9s availability.
What is the maintenance window in five 9s availability?
Five 9s availability means that a company’s apps or websites are operational 99.999% of the time. This equates to about five minutes of downtime per year. For most companies, this is an acceptable amount of downtime. However, for companies that rely heavily on uptime, such as utilities, telecommunications, e-commerce, and financial services companies, five minutes of downtime can be costly.
To achieve five 9s availability, companies must have a robust server infrastructure in place. They must also have a robust maintenance schedule. The maintenance window is the time during which the servers are taken offline for maintenance.
Five 9s availability is often used as a goal for critical systems, but it is not always achievable or necessary. In many cases, four nines (99.99%) or even three nines (99.9%) availability may be sufficient.
How do you calculate five 9s availability?
To calculate the amount of acceptable downtime for five 9s of availability, you need to know the total number of minutes of uptime you want for a system, multiply that by 99.999%, and subtract the result from the total desired uptime. The formula is:
Total desired uptime - (0.99999 * Total desired uptime) = acceptable downtime
For example, if a system should be always on that means it should be running for 525,600 minutes per year (365 days * 24 hours/day * 60 minutes/hour). The formula to calculate acceptable downtime is:
525,600 - (0.99999 * 525,600) = 525,600 - 525,594.75 = 5.25 minutes, or 5 minutes, 15 seconds per year, which is about 6 seconds per week
Four 9s of availability would equate to:
525,600 - (0.9999 * 525,600) = 52.5 minutes, or 52 minutes, 30 seconds per year – about 1 minute per week
What are the components of five 9s availability?
As mentioned above, nines are a unit of measurement used to describe the reliability of a system or process. The term "five 9s" refers to a reliability level of 99.999%. This means that the system or process is operational 99.999% of the time. This is an incredibly high level of reliability, and is often used as a benchmark for mission-critical systems.
Achieving five 9s availability is often difficult and expensive, as it requires a high level of redundancy and careful planning. For example, a power grid that is designed for five 9s availability will typically have backup generators and power lines that can be used if the primary system fails.
Two other considerations related to achieving five 9s availability are Mean Time Between Failures and Service Level Agreements.
What is Mean Time Between Failures (MTBF)?
MTBF is a key consideration when thinking about the level of availability you need. It’s a measure of the reliability of a system or component and is usually expressed in hours. A system with a long MTBF is considered more reliable than one with a shorter MTBF.
Systems with a high MTBF are often designed with redundancy in mind. Redundant components can take over the function of a failed component, allowing the system to continue operating with little or no downtime.
The flip side to MTBF is Mean Time To Repair (MTTR). MTTR is a measure of how long it takes to repair a failed component. MTBF measures the reliability of the service or the component, whereas MTTR measures the efficiency of its repair. If MTTR takes a lot of time, then systems must be designed with redundancy and failover in mind. This means that if one component fails, another can take its place with no impact (or minimal impact) on the system as a whole.
What is a Service Level Agreement (SLA)?
An SLA is an agreement between a service provider and a customer that defines the terms of the service, including availability and uptime. Some industries have standards for what they consider acceptable SLAs. In other cases, it is up to the provider and customer to agree to a service level. Violating an SLA often includes a financial penalty if the service provider exceeds the amount of downtime the customer agrees to.
A smarter approach
One of the ways service providers can manage and track their adherence to SLAs is by using service level objectives so that they are alerted when they are getting close to violating the SLA.
To avoid spreading your resources too thinly, you need to set realistic targets for the level of availability each service actually requires. These targets are called “Service Level Objectives” or “SLOs” for short. A SLO is the proper level of reliability for a given service. Start by asking yourself a few questions:
- What are the top two or three mission-critical services? For these services, you may opt for an SLO of four or five 9s.
- What services are of lower priority? Here, SLOs of three or four 9s are likely sufficient.
If you are an e-commerce site, for example, you may place a higher priority on the checkout experience than simply browsing your catalog. You may therefore choose an SLO of five 9s for the checkout service, and four 9s for browsing. Or perhaps you have a development environment with an SLO of three or four 9s and a production environment with an SLO of five 9s.
As you can see in this example, you may end up with a mix of SLO targets ranging from three to five 9s for different services. With this approach, you’ll be keeping customers happy without wasting time and money trying to achieve a level of performance that doesn’t deliver commensurate benefits. You’ve also determined the critical services that are worth extra investment for automation, redundancy, testing, and other reliability enhancements. That’s a far wiser approach than arbitrarily setting SLOs of five 9s for everything.
Achievable goals vs. aspirational goals
Unfortunately, the work doesn't end with simply setting reliability targets. The goals you set may be your aspiration, but you have hard work to do to achieve these goals. You may want to benchmark yourself today and look at your historical track record with these metrics. Catalog the risks that might affect your service—external outages, software updates, network congestion, etc.—and try to quantify their impact in terms of reliability. For each risk you identify, calculate the estimated frequency and the time to detect and resolve the problem. This will give you an idea of the expected downtime per year associated with each of them, and their potential impact on your customer base – and determine whether the cost of achieving higher reliability and availability is worth it. By aggregating this information, you can create a model for the achievability of your goals.
Once you’ve set the benchmark, you’ll see a clear gap between today’s risk profile and your desire to deliver a more reliable service. Starting with the biggest risk, ask your team, “How could we proactively mitigate this risk?” For example, you might find a single point of failure that needs redundancy. Each of these mitigations can be listed on your reliability roadmap and added into the rest of the feature priorities for the release. Bubbling up specific, quantifiable reliability improvements is a great way to get them funded.
Choose your 9s wisely
More nines is all the rage, but don’t jump on the bandwagon without thinking it through. As you invest time, money, and employee resources into achieving higher reliability, you will inevitably reach a point of diminishing returns, and passing that point is a waste of your company’s precious resources. Site reliability engineering, after all, is about achieving balance given a limited set of resources.

The better way to set SLOs for availability—or any other critical service objective, such as latency, durability, etc.—is to remember it’s not about more nines; it’s about the right number of nines to deliver a great customer experience. To execute this smarter approach, first determine which services deserve five 9s. Choose wisely, and be prepared to invest your energy and resources more heavily there. Second, ensure that you define clear, reasonable SLOs for all your services so your teams know how to prioritize their time.
If you’re ready to dig a bit deeper into setting SLOs, check out the next blog post, Optimizing Cloud Costs through Service Level Definitions.
Image Credit: Takahiro Sakamoto on Unsplash
Share:







Do you want to add something? Leave a comment